
티스토리 뷰
윈도우 환경에서 파이참을 활용하여 GloVe를 사용해보고자 한다.
GloVe는 2014년에 나온 임베딩 기법으로
말뭉치 전체의 통계 정보와 임베딩된 단어 벡터 간 유사도를 활용하고자 하는 시도이다.
자세한 내용은 다른 블로그에서 멋지게 설명하고 있으니 그곳을 참조하면 좋을 것 같다.
먼저 GloVe를 윈도우 환경에서 사용하기 위해 몇번의 시도를 하였지만
좀처럼 해결이 되지 않았다.
그래서 찾은 해결(?), 다른 방안으로 해보았다.
우선 인스톨 하는 패키지는 glove-python-binary 이다.
GloVe가 설치가 되면 이제 이전 블로그에서 생성한 코퍼스 파일을 읽어 학습을 시켜보도록 한다.
코드
import numpy as np
from glove import Glove
from glove import Corpus
from tqdm import tqdm
corpus_fname = 'D:/Data/embedding/data/tokenized/corpus_mecab.txt'
corpus_model = 'D:/Data/embedding/data/word-embeddings/glove/corpus.model'
glove_model = 'D:/Data/embedding/data/word-embeddings/glove/glove.model'
def make_corpus(load=False):
if load:
_corpus = Corpus.load(corpus_model)
else:
corpus = [sent.strip().split(" ") for sent in tqdm(open(corpus_fname, 'r', encoding='utf-8').readlines())]
_corpus = Corpus()
_corpus.fit(corpus, window=10)
_corpus.save(corpus_model)
return _corpus
def train(corpus=None, train=True):
if train:
print('Dict size: %s' % len(corpus.dictionary))
print('Collocations: %s' % corpus.matrix.nnz)
_glove = Glove(no_components=100, learning_rate=0.05)
_glove.fit(corpus.matrix, epochs=10, no_threads=4, verbose=True)
_glove.add_dictionary(corpus.dictionary)
_glove.save(glove_model)
else:
print('Loading pre-trained GloVe model')
_glove = Glove.load(glove_model)
return _glove
corpus = make_corpus(load=False)
glove = train(corpus, train=True)
# https://projector.tensorflow.org/ 에서 보기 위해 파일 생성
np.savetxt('D:/Data/embedding/data/word-embeddings/glove/glove-vector.tsv', glove.word_vectors, delimiter='\t')
with open('D:/Data/embedding/data/word-embeddings/glove/glove-metadata.tsv', 'w', encoding='utf-8') as f:
for key in glove.dictionary.keys():
f.write(f"{key}\n")
make_corpus() 코퍼스를 읽어 단어-문맥 행렬을 만든다.
이 때 행렬을 만드는 고려 대상 문맥의 길이가 window 사이즈가 된다.
train()은 임베딩 차원을 100으로 10 epochs 학습을 진행한다.
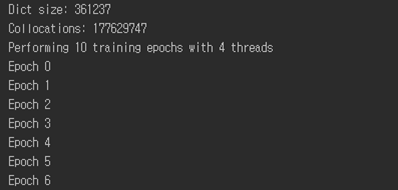
결과는 아래와 같이 수행된다.
마지막에 실행되는 코드를 통해 https://projector.tensorflow.org/에서 시각화를 해 볼 수도 있다.

학습된 모델을 로딩하여 특정 단어와 가까운 단어 목록을 추출해 볼 수도 있다.
코드1
from glove import Glove
glove = Glove.load('D:/Data/embedding/data/word-embeddings/glove/glove.model')
print(glove.most_similar('최민식', number=10))
print(glove.most_similar('남대문', number=10))
print(glove.most_similar('아이언맨', number=10))
print(glove.most_similar('김구', number=10))
print(glove.most_similar_paragraph(['아이유', '앨범'], number=10))결과1
[('김윤석', 0.9080894769129085), ('송강호', 0.9068375250988043), ('설경구', 0.8972406875244299), ('이병헌', 0.8883518999901475), ('하정우', 0.8638950995301851), ('말아톤', 0.8526737414607245), ('안성기', 0.8442578282034814), ('정재영', 0.8380447297832779), ('전도연', 0.8365803704598296)]
[('을지로', 0.8156968466503992), ('종로', 0.80800317609525), ('세종대로', 0.7784934170131148), ('명동', 0.7750919685710469), ('소공동', 0.757427997117841), ('동대문', 0.7368746104500291), ('태평로', 0.729786077767001), ('장충동', 0.7178131933634985), ('중구', 0.7106360179756906)]
[('헐크', 0.7198300099026707), ('어벤져스', 0.7180435811064126), ('마블', 0.7083302979141264), ('고질라', 0.6767901547691814), ('어벤저스', 0.674166764562905), ('스파이더맨', 0.657007482878586), ('엔드게임', 0.656775408415713), ('스타크', 0.6415797517366958), ('퍼니셔', 0.6384300739349467)]
[('김규식', 0.8485585233828001), ('이승만', 0.8402375042155611), ('백범', 0.8221169474742005), ('여운형', 0.7979084065479319), ('조소앙', 0.7688555255149967), ('장덕수', 0.7587589407188101), ('임정', 0.7503308608510417), ('안창호', 0.7419342732231041), ('이시영', 0.7177978194942772)]
[('아이유', 0.9861665140101541), ('박효신', 0.8250590602853678), ('변진섭', 0.820571293400712), ('신승훈', 0.8132925730228597), ('에일리', 0.806867414130659), ('임창정', 0.7977050443950147), ('성시경', 0.794305917970237), ('백지영', 0.793807302871245), ('버스커', 0.7934439355114976), ('다비치', 0.7883801517499768)]
혹은 https://github.com/ratsgo/embedding/blob/master/models/word_eval.py 의 코드를 참조하여 변형시킨 예도 있다.
코드2
from glove import Glove
from konlpy.tag import Mecab
class WordEmbeddingSimilarWord:
def __init__(self, model_file, dim=100):
self.model = Glove.load(model_file) # 모델 로드
self.dim = dim
self.tokenizer = Mecab(dicpath='C:/mecab/mecab-ko-dic')
self.dictionary = self.load_dictionary(self.model)
def load_dictionary(self, model):
return model.dictionary
def get_sentence_vector(self, sentence):
tokens = self.tokenizer.nouns(sentence)
token_vecs = []
for token in tokens :
if token in self.dictionary :
token_vecs.append(token)
return token_vecs
def most_similar(self, sentence, topn=10):
token_vecs = self.get_sentence_vector(sentence)
return self.model.most_similar_paragraph(token_vecs, number=topn)
wv = WordEmbeddingSimilarWord("D:/Data/embedding/data/word-embeddings/glove/glove.model", 100)
print(wv.most_similar("슈퍼맨 배트맨", topn=5))
print(wv.most_similar("임시정부 김구", topn=5))결과2
[('슈퍼맨', 0.9784950576883523), ('배트맨', 0.8991950138163745), ('저스티스', 0.8151436692930096), ('비긴즈', 0.7025553946625477), ('마블', 0.639773379435444)]
[('김구', 0.923460705555689), ('임시', 0.8640857705280318), ('이승만', 0.7868115704207749), ('김규식', 0.7822900987334844), ('임정', 0.7699769497481892)]
그런데 그냥 실행하게 되면 아래와 에러가 발생할 수 있다.
TypeError: int() argument must be a string, a bytes-like object or a number, not 'dict_keys'그러할 땐 glove.py를 수정해줘야 한다.
대략 166~167라인에 보면
word_ids = np.array(cooccurrence.keys(), dtype=np.int32)
values = np.array(cooccurrence.values(), dtype=np.float64)이와 같은 코드를 아래와 같이 수정한다.
word_ids = np.array(list(cooccurrence), dtype=np.int32)
values = np.array(list(cooccurrence.values()), dtype=np.float64)
그럼 이상없이 출력이 될 것이다.
끝.
'ML&DL' 카테고리의 다른 글
| 토픽모델링 - LDA (gensim 사용) (4) | 2020.08.19 |
|---|---|
| 임베딩 - FastText (한글 자소 분리) (0) | 2020.08.16 |
| mecab 사전 우선순위 조정 (3) | 2020.08.13 |
| 임베딩 - FastText (2) | 2020.08.13 |
| Word2Vec - 시각화 2 (1) | 2020.08.12 |
- Total
- Today
- Yesterday
- 사이퍼
- Knowledge Graph
- TDB
- sparql
- stardog
- networkx
- pyvis
- property graph
- 타임리프
- rdfox
- neosemantics
- django
- 장고
- 트리플
- 지식그래프
- 그래프 데이터베이스
- Neo4j
- 트리플 변환
- 스프링부트
- LOD
- RDF
- TBC
- Ontology
- 온톨로지
- Linked Data
- Thymeleaf
- cypher
- RDF 변환
- TopBraid Composer
- 지식 그래프
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |