
티스토리 뷰
형태소 분석기인 mecab에 사용자 사전을 정의하여 사용하다보면
간혹 사전을 생성했음에도 사전에 입력한 대로 결과가 나오지 않고 단어가 분리되어 나올 때가 있다.
실제로 그러한 경우를 재현해 보도록 하겠다.
환경은 Windows 에 파이참을 사용한다.
윈도우 환경 + 파이참 에서 mecab을 사용하는 방법은 아래의 내용을 참고하세요
https://joyhong.tistory.com/127
윈도우 환경에서 mecab 설치 후 파이참(PyCharm) 에서 사용하기
윈도우에서 파이참을 사용하여 개발할 때 형태소 분석기 중 하나인 mecab을 사용하려면 몇가지 설치와 실행을 통해서 가능하다. 먼저 다운 받아야 할 것은 1. mecab-ko-msvc 2. mecab-ko-dic-msvc.zip 이렇게
joyhong.tistory.com
사용지 사전 생성 전
# -*- coding: utf-8 -*-
from konlpy.tag import Mecab
text = "홍길동은 어제 대통령표창을 받았다."
tokenizer = Mecab(dicpath='C:/mecab/mecab-ko-dic')
tagged = tokenizer.pos(text)
nouns = [s for s, t in tagged if t in ['SL','NNG','NNP']]
print(nouns)위의 코드를 실행하면 결과는
['홍길동', '대통령', '표창']이렇게 3개의 명사로 나오게 된다.
여기서 내가 원하는 것은 "대통령표창" 이라는 단어가 하나의 복합명사로 추출을 하고 싶다.
그래서 사전에 추가해보도록 한다.
mecab이 설치된 폴더 하위에 user-dic 이라는 폴더가 있는데 그안을 살펴보면 nnp.csv 파일을 찾을 수 있다.

이 파일을 편집기로 열어 추가하고자 하는 단어를 입력해 주면 된다.
대우,,,,NNP,*,F,대우,*,*,*,*
구글,,,,NNP,*,T,구글,*,*,*,*
대통령표창,,,,NNP,*,T,대통령표창,*,*,*,*처음 2개는 원래 있던 내용이고
세번째에 대통령표창이라는 단어를 추가하였다.
이후 파일을 저장 후 powershell을 실행하여 스크립트를 실행하면 된다.
여기서는 add-userdic-win.ps1 파일을 실행한다.
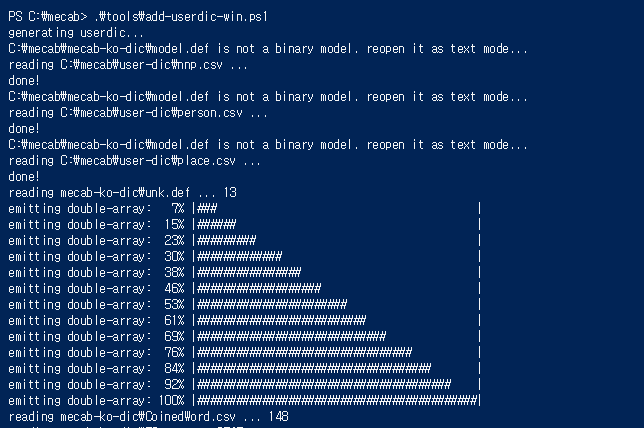
위와 같이 쭉 뭔가 실행되고 나면 mecab-ko-dic 폴더 아래에 user-nnp.csv 파일이 생성되는 것을 확인할 수 있다.
그럼 다시 파이참으로 돌아가 처음 코드를 실행해보도록 한다.
['홍길동', '대통령', '표창']결과는 이전과 같다.
사전 추가가 실패한 것인가?
그렇지는 않다.
mecab-ko-dic 폴더 아래에 user-nnp.csv 파일을 편집기로 열어보면
대우,1786,3545,3821,NNP,*,F,대우,*,*,*,*,*
구글,1786,3546,2953,NNP,*,T,구글,*,*,*,*,*
대통령표창,1786,3546,2953,NNP,*,T,대통령표창,*,*,*,*이렇게 생성되어 있는 것을 볼 수 있다.
여기서 내가 생성한 단어가 우선적으로 결과로 나오게 하기 위해서는
우선 순위를 변경해 주면 된다.
대통령표창 다음에 3개의 숫자들이 나오는데
3번째 숫자가 단어비용에 대한 값이다.
이 부분을 낮게 조정할 수록 비용이 적게 들어 우선순위가 올라가게 된다.
그럼 대통령표창에 2953 이라는 숫자를 0으로 변경해보자.(적절한 값으로 변경 하면 됩니다.)
대우,1786,3545,3821,NNP,*,F,대우,*,*,*,*,*
구글,1786,3546,2953,NNP,*,T,구글,*,*,*,*,*
대통령표창,1786,3546,0,NNP,*,T,대통령표창,*,*,*,*위와 같이 변경 후 파일을 저장한 뒤 사전에 반영하기 위해서는 컴파일을 해야 한다.
컴파일을 tool 폴더 아래에 compile-win.ps1 파일을 실행하면 된다.

컴파일이 실행되고 완료가 되면
다시 파이참으로 돌아가 분석을 실행한다.
['홍길동', '대통령표창']이번에는 원하는대로 결과가 나왔다.
위와 같은 방식으로 사전을 추가하고 우선순위를 조정하면서 사용이 가능하다.
그렇다면 만약 나중에 새로운 단어를 사전에 추가해야할 경우가 생기면
그전에 조정한 우선순위는 어떻게 되는가?
별도로 저장해 놓지 않으면 이전에 조정한 우선순위 정보는 없어지니까 조심해야 한다.
그래서 이전에 생성된 mecab-ko-dic 폴더 안에 있는 user-nnp.csv 파일을
적절한 이름으로 변경해 놓고
새롭게 추가할 단어들을 user-dic 폴더 안에 있는 nnp.csv 혹은 person 이나 place.csv에 추가하여 위와 같이 사전을 추가하면 (이전에 입력된 내용은 삭제)
이전의 정보를 유지하면서 사용이 가능하다.
'ML&DL' 카테고리의 다른 글
| 토픽모델링 - LDA (gensim 사용) (4) | 2020.08.19 |
|---|---|
| 임베딩 - FastText (한글 자소 분리) (0) | 2020.08.16 |
| 임베딩 - FastText (2) | 2020.08.13 |
| Word2Vec - 시각화 2 (1) | 2020.08.12 |
| Word2Vec - 시각화(t-SNE, PCA) (2) | 2020.08.12 |
- Total
- Today
- Yesterday
- stardog
- neosemantics
- 스프링부트
- rdfox
- TopBraid Composer
- Neo4j
- 트리플 변환
- 타임리프
- sparql
- Knowledge Graph
- Linked Data
- TBC
- LOD
- Ontology
- 사이퍼
- property graph
- 트리플
- django
- 그래프 데이터베이스
- 온톨로지
- cypher
- 지식 그래프
- networkx
- 장고
- TDB
- 지식그래프
- Thymeleaf
- RDF 변환
- pyvis
- RDF
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |