
티스토리 뷰
토픽모델링 기법 중에 하나인 잠재 디리클레 할당(Latent Dirichlet Allocation, LDA)을 이용하여 토픽이 어떻게 존재하는지 살펴볼 예정이다.
데이터로는 공훈전자사료관에서 제공하는 독립유공자공적조서를 활용한다.
https://e-gonghun.mpva.go.kr/user/RewardOpenAPI.do?goTocode=50001
공훈전자사료관
국가보훈처 공훈전자사료관은 사용자가 응용프로그램을 쉽고 용이하게 개발·활용할 수 있도록 데이터를 일정한 형식으로 개방하고 있습니다. 아래 내용을 참조하여 데이터를 활용하시기 바랍
e-gonghun.mpva.go.kr
위 사이트에서 내려받아 구성해 놓은 데이터는 아래의 링크에서 다운로드 받을 수 있다.
파일은 csv 파일로 이름, 생년, 몰년, 성별, 공적개요만을 저장해 놓았다.
,title,birth_day,death_day,gender,description
0,가네코 후미코,1903-01-25,1926-07-23,여,"1922년 5월~1923년 3월, 일본(日本) 동경(東京)에서 박열(朴烈)과 함께 흑도회(黑濤會)의 기관지 『흑도(黑濤)』, 흑우회(黑友會)의 기관지 『태(太)ィ선인(鮮人)』, 『현사회(現社會)』를 간행하여 무정부주의의 선전과 회원 규합에 노력함. 1923년 4월부터는 박열(朴烈)이 주도한 무정부주의 단체 ‘불령사’(‘不逞社’)에 가입하여 활동하다 동년(同年) 9월 3일 동경(東京) 대지진(大地震) 직후 체포(逮捕)된 후 1924년 2월 15일 박열(朴烈)의 ‘대역사건(大逆事件)’으로 기소되어 1926년 3월 25일 사형을 받음. 이후 무기징역(無期懲役)으로 감형되었으나 1926년 7월 23일 우쓰노미야형무소[우도궁형무소(宇都宮刑務所)] 도치기지소[회목지소(栃木支所)]에 수감 중 옥중 순국(獄中殉國)함.1922년 2월부터 박열과 의기투합하여 일본 제국주의에 반대하는 활동을 시작하였다. 5월 경 흑도회에 가입했고 7월부터는 박열과 함께 기관지 『흑도』의 발간책임을 맡았다. 9월에는 흑우회를 조직해 사상연구와 연설회 등을 추진하면서 기관지 『민중운동(民衆運動)』을 한글로 발행하였다. 12월에는 『후토이센진』을 창간했고, 1923년 3월 『현사회』라는 이름으로 개칭하여 지속적으로 발간하였다. 1923년 4월 무정부주의 운동가들을 규합하여 불령사를 조직하였다. 불령사는 한국 내 형평운동을 지지하는 한편 노동운동을 적극 지원하는 등 무정부주의에 입각한 항일투쟁을 전개하였다. 이즈음 의열단과 함께 의열투쟁을 추진했는데, 폭탄을 도쿄로 반입하여 일왕과 정부 요인을 암살하려는 계획을 세우기도 했다. 1923년 9월 도쿄대지진 직후 보호감속 명목으로 도쿄 세타가야(世田谷) 경찰서에 구금되었다. 취조 도중 폭탄 반입 사실이 알려지게 되어 이른바 ‘대역사건’의 주모자가 되었다. 구금 중 박열과 결혼하고 일제 사법당국을 향해 항일 활동을 떳떳하게 항변했으며 재판 중 만세를 부르기도 하였다. 1926년 3월 25일 대심원 제1특별형사부에서 이른바 ‘형법 제73조(大逆罪) 및 폭발물취체규칙위반’ 등으로 사형을 언도받았다. 4월 무기징역으로 감형되어 옥고를 치르던 중 옥중에서 순국하였다. 정부는 2018년에 건국훈장 애국장을 추서하였다."
1,가재연,1923-04-08,1945-03-29,남,"1944. 4월 인천상업학교 출신 명치대학생(明治大學生)인 송재필(宋在弼)의 학병반대 결의문(學兵反對決議文)이 적경(敵警)에게 탐지되어 송재필과 동급생들이 한국인학생 친목회를 결성한 것을 트집잡아 체포되어 고문으로 순국하였다고 함.충남 서산(瑞山) 사람이다. 인천상업학교 재학중 한국인 학생들에 대한 차별대우를 뼈저리게 느끼면서 한국인 학생끼리 비밀리에 친목회를 조직하고 고락을 함께 하기로 결의하였다. 이들은 일본인 교장 야마모도의 억압에 반대하면서, 학교에서 못하게 하는 졸업앨범을 제작하여 졸업 후에도 항일운동을 계속하기로 굳게 약속하였다. 그런데 이 학교 출신으로 일본 명치대에 진학한 송재필(宋在弼)이 보성전문학교(普成專門學校)에 다니는 친구를 방문하여 학병 반대운동을 전개하기로 결의하고, 각처에 편지로 연락하다가 충북 영동서에 발각되었다. 이에 따라 친목회에 가입하였던 그를 비롯한 고윤희·김여수·김형설·정태윤 등의 동기생들이 1944년 1월부터 속속 영동서에 붙잡혔다. 이들은 소위 치안유지법 위반 혐의로 대전검사국에 송치되었으며, 그는 1945년 3월 29일 일경의 모진 고문과 옥고의 여독으로 대전형무소에서 옥사 순국하였다. 정부에서는 고인의 공훈을 기리어 1991년에 건국훈장 애족장(1986년 대통령표창)을 추서하였다."
2,가재창,1897-11-02,1936-05-31,남,"1918. 3월 대한독립청년단(大韓獨立靑年團) 안면도지단(安眠島支團)을 설치하고 군자금모집활동하다가 일경에 피체되어 1920. 10. 18 공주지방법원(公州地方法院)에서 정치범처벌령 반역으로 징역 1년 집행유예 1년형을 받아 2년 8월의 활동한 사실이 확인됨.충남 서산(瑞山, 현 태안) 사람이다. 1919년 3·1독립운동 당시 서산군 안면도(安眠島)의 만세시위를 주도하였으며, 이후 비밀결사 대한독립청년단(大韓獨立靑年團)에 가입하여 항일활동을 폈다. 대한독립청년단은 윤종정(尹宗楨)·안영식(安英植) 등 평양(平壤)의 기독교인들을 중심으로 조직된 임시정부 지원단체로서 주요 활동은 임시정부와의 통신연락, 군자금 모집, 비밀출판 등이었다. 그는 1919년 이종성(李鍾聲)·이종헌(李鍾憲)·임정호(林楨鎬)·오몽근(吳夢根) 등과 함께 서산군 안면도(安眠島)에 대한독립청년단의 지단으로서 독립지단(獨立支團, 일명 決死團)을 조직하였다. 이들은 이후 각 가정의 청년들을 역방하며 동지규합에 힘써 단원이 20여명에 이르렀으며 군자금 모집에 착수하여 250원의 군자금을 모금하였다. 그러던 중 그는 동지들과 함께 1920년 3월 일경에 붙잡혀 동년 10월 공주지방법원에서 소위 정치범처벌령 위반으로 징역 1년, 집행유예 2년형을 언도받았다. 정부에서는 고인의 공훈을 기리어 1990년에 건국훈장 애족장(1982년 대통령표창)을 추서하였다."
3,감익룡,1887-12-29,1946-09,남,"1910년 경술국치(庚戌國恥)를 통탄(痛歎)하여 매일신보(每日申報)에 애국 사상(愛國思想)을 고취(鼓吹)하고 독립투사(獨立鬪士)를 양성하는 무관학교 설립(武官學校設立)에 참가하여 활동하다가 일경(日警)에게 체포되어 2년 6월의 징역형을 받고 옥고를 치렀으며 출옥 후에도 적의 감시와 취체(取締)가 심하여져서 상해(上海)로 탈출하여 세월을 보내다가 8.15광복(光復)을 맞아 환국(還國)한 사실이 확인됨.황해도 송화(松禾)군 연중(蓮中)면 온수(溫水)리에서 태어났다. 1907년 4월 양기탁(梁起鐸)·안창호(安昌浩)·전덕기(全德基) 등을 중심으로 국권회복을 위한 비밀결사로서 신민회(新民會)가 창립되자 이에 가입하여 황해도 지회에서 활동하였다. 신민회가 만주에 무관학교(武官學校)를 설립하고 독립군기지 창건사업을 추진할 때 이에 적극 참가하여 1910년 12월 초순 만주 안동현(安東縣)을 독립군기지 후보지로 시찰하여 물색하고, 평안북도 용천(龍川)의 신민회 회원인 김용규(金容奎)·고일청(高一淸)·김용삼(金容參)·김희록(金熙錄)·김성주(金成柱) 등 동지들과 함께 1910년 12월 하순 연락근거지를 만드는데 성공하였다. 감익룡 등은 안동현에서 상업을 경영하면서 안동이 만주 중국으로 가는 통로이므로 이곳에 하나의 거점을 설립하여 한편으로는 다수의 청년들을 북경무관학교에 입학토록 알선하고 그 입학자금을 공급하며, 다른 한편으로는 서간도에 세울 독립군기지와 무관학교에 갈 이주민을 모집하는 사업을 하였다. 일제가 1911년 1월 신민회의 무관학교와 독립군기지 창건운동을 탄압하기 위하여 관계인사를 검거한 소위 「양기탁 등 16명 보안법위반사건」으로 징역 1년 6개월을 언도받고 경성형무소에서 옥고를 치렀다. 정부에서는 고인의 공훈을 기리어 1990년에 건국훈장 애족장(1977년 대통령표창)을 추서하였다."
먼저 이 파일의 공적개요를 형태소 분서기 mecab으로 명사만을 추출하겠다.
# -*- coding: utf-8 -*-
from konlpy.tag import Mecab
from tqdm import tqdm
import re
import pickle
import csv
def clean_text(text):
"""
한글, 영문, 숫자만 남기고 제거한다.
:param text:
:return:
"""
text = text.replace(".", " ").strip()
text = text.replace("·", " ").strip()
pattern = '[^ ㄱ-ㅣ가-힣|0-9|a-zA-Z]+'
text = re.sub(pattern=pattern, repl='', string=text)
return text
def get_nouns(tokenizer, sentence):
"""
단어의 길이가 2이상인 일반명사(NNG), 고유명사(NNP), 외국어(SL)만을 반환한다.
:param tokenizer:
:param sentence:
:return:
"""
tagged = tokenizer.pos(sentence)
nouns = [s for s, t in tagged if t in ['SL', 'NNG', 'NNP'] and len(s) > 1]
return nouns
def tokenize(df):
tokenizer = Mecab(dicpath='C:/mecab/mecab-ko-dic')
processed_data = []
for sent in tqdm(df['description']):
sentence = clean_text(sent.replace('\n', '').strip())
processed_data.append(get_nouns(tokenizer, sentence))
return processed_data
def save_processed_data(processed_data):
"""
토큰 분리한 데이터를 csv로 저장
:param processed_data:
:return:
"""
with open('./data/tokenized_data.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
for data in processed_data:
writer.writerow(data)
if __name__ == '__main__':
# 유공자 공훈조서 데이터를 읽어들인다.
df = pd.read_csv('./data/historical_records.csv')
processed_data = tokenize(df) # description 부분을 토크나이징 한다.
# 토큰 분리한 데이터를 저장
save_processed_data(processed_data)
이 코드를 실행한 결과로 생성되는 tokenized_data.csv 파일은 아래에서 제공한다.
일본,동경,박열,흑도회,기관지,흑도,흑우회,기관지,태선인,현사회,간행,무정부주의,선전,회원,규합,노력,박열,주도,무정부주의,단체,불령사,가입,활동,동년,동경,대지진,직후,체포,박열,대역사건,기소,사형,이후,무기징역,감형,우쓰노미야형무소,우도궁형무소,도치기지소,회목지소,수감,옥중,순국,박열,의기투합,일본,제국주의,반대,활동,시작,흑도회,가입,박열,기관지,흑도,발간,책임,흑우회,조직,사상연구,연설회,추진,기관지,민중운동,한글,발행,후토이센진,창간,현사회,이름,개칭,지속,발간,무정부주의,운동가,규합,불령사,조직,불령사,한국,형평운동,지지,한편,노동운동,적극,지원,무정부주의,입각,항일투쟁,전개,의열단,의열투쟁,추진,폭탄,도쿄,반입,일왕,정부,요인,암살,계획,도쿄대지진,직후,보호,감속,명목,도쿄,세타가야,경찰서,구금,취조,도중,폭탄,반입,사실,대역사건,주모자,구금,박열,결혼,일제,사법,당국,항일,활동,항변,재판,만세,대심원,특별형사부,형법,폭발물취체규칙위반,사형,언도,무기징역,감형,옥고,옥중,순국,정부,건국훈장,애국장,추서
인천상업학교,출신,명치대학생,송재필,학병,반대,결의문,적경,탐지,송재필,동급생,한국인,학생,친목회,결성,트집,체포,고문,순국,충남,서산,사람,인천상업학교,재학,한국인,학생,차별,대우,한국인,학생,비밀리,친목회,조직,고락,결의,일본인,교장,야마,모도,억압,반대,학교,졸업앨범,제작,졸업,항일운동,계속,약속,학교,출신,일본,명치,진학,송재필,보성전문학교,친구,방문,학병,반대운동,전개,결의,각처,편지,연락,충북,동서,발각,친목회,가입,고윤희,김여수,형설,정태윤,동기생,동서,치안유지법,위반,혐의,대전,검사국,송치,일경,고문,옥고,여독,대전형무소,옥사,순국,정부,고인,공훈,건국훈장,애족장,대통령표창,추서
대한독립청년단,안면,지단,설치,군자금,모집활동,일경,피체,공주,지방,법원,정치범,처벌,반역,징역,집행유예,활동,사실,확인,충남,서산,태안,사람,독립운동,당시,서산군,안면도,만세,시위,주도,이후,비밀결사,대한독립청년단,가입,항일활동,독립청년단,윤종정,안영식,평양,기독교,중심,조직,임시정부,지원,단체,주요,활동,임시정부,통신,연락,군자금,모집,비밀,출판,이종성,이종헌,임정호,오몽근,서산군,안면도,독립청년단,지단,독립,지단,조직,이후,가정,청년,역방,동지,규합,단원,군자금,모집,착수,군자금,모금,동지,일경,동년,공주지방법원,정치범,처벌,위반,징역,집행유예,언도,정부,고인,공훈,건국훈장,애족장,대통령표창,추서
그럼 이제 두번째 단계로 명사만으로 구성된 파일을 읽은 뒤
최적의 토픽이 몇개가 좋은지 체크를 해본다.
최적의 토픽 개수를 찾기 위해 coherence를 c_v로 계산하여 찾아보도록 한다.
# -*- coding: utf-8 -*-
from konlpy.tag import Mecab
from tqdm import tqdm
import re
from gensim.models.ldamodel import LdaModel
from gensim.models.callbacks import CoherenceMetric
from gensim import corpora
from gensim.models.callbacks import PerplexityMetric
import logging
import pickle
import pyLDAvis.gensim
from gensim.models.coherencemodel import CoherenceModel
import matplotlib.pyplot as plt
def compute_coherence_values(dictionary, corpus, texts, limit, start=2, step=3):
"""
Compute c_v coherence for various number of topics
Parameters:
----------
dictionary : Gensim dictionary
corpus : Gensim corpus
texts : List of input texts
limit : Max num of topics
Returns:
-------
model_list : List of LDA topic models
coherence_values : Coherence values corresponding to the LDA model with respective number of topics
"""
coherence_values = []
model_list = []
for num_topics in range(start, limit, step):
model = LdaModel(corpus=corpus, id2word=dictionary, num_topics=num_topics)
model_list.append(model)
coherencemodel = CoherenceModel(model=model, texts=texts, dictionary=dictionary, coherence='c_v')
coherence_values.append(coherencemodel.get_coherence())
return model_list, coherence_values
def find_optimal_number_of_topics(dictionary, corpus, processed_data):
limit = 40;
start = 2;
step = 6;
model_list, coherence_values = compute_coherence_values(dictionary=dictionary, corpus=corpus, texts=processed_data, start=start, limit=limit, step=step)
x = range(start, limit, step)
plt.plot(x, coherence_values)
plt.xlabel("Num Topics")
plt.ylabel("Coherence score")
plt.legend(("coherence_values"), loc='best')
plt.show()
if __name__ == '__main__':
processed_data = [sent.strip().split(",") for sent in tqdm(open('./data/tokenized_data.csv', 'r', encoding='utf-8').readlines())]
# 정수 인코딩과 빈도수 생성
dictionary = corpora.Dictionary(processed_data)
# 출현빈도가 적거나 자주 등장하는 단어는 제거
dictionary.filter_extremes(no_below=10, no_above=0.05)
corpus = [dictionary.doc2bow(text) for text in processed_data]
print('Number of unique tokens: %d' % len(dictionary))
print('Number of documents: %d' % len(corpus))
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
# 최적의 토픽 수 찾기
find_optimal_number_of_topics(dictionary, corpus, processed_data)
dictionary.filter_extremes()를 이용하여 출현빈도가 적거나 코퍼스에서 많이 등장하는 단어는 제거하였다.
coherence를 계산할 때는 토픽의 개수를 2~40개 사이로 6step으로 나누어 진행하도록 설정하였다.
그 결과는 토픽이 14개일 때 coherence 점수가 0.56정도라고 나왔다.
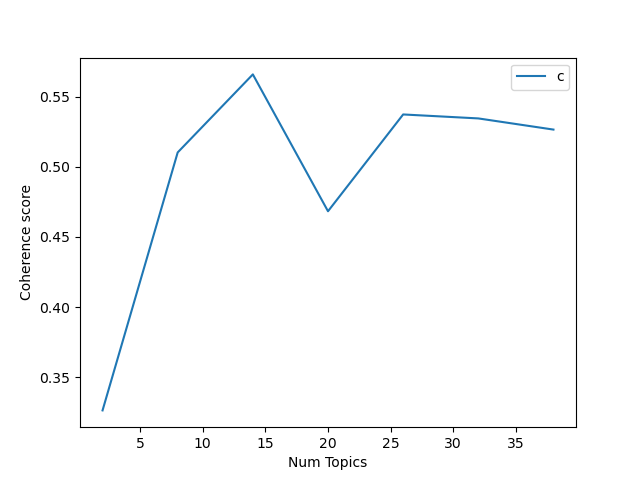
그럼 이제 토픽수를 14개로 정하고 학습을 시키도록 한다.
# -*- coding: utf-8 -*-
from konlpy.tag import Mecab
from tqdm import tqdm
import re
from gensim.models.ldamodel import LdaModel
from gensim.models.callbacks import CoherenceMetric
from gensim import corpora
from gensim.models.callbacks import PerplexityMetric
import logging
import pickle
import pyLDAvis.gensim
from gensim.models.coherencemodel import CoherenceModel
import matplotlib.pyplot as plt
if __name__ == '__main__':
processed_data = [sent.strip().split(",") for sent in tqdm(open('./data/tokenized_data.csv', 'r', encoding='utf-8').readlines())]
# 정수 인코딩과 빈도수 생성
dictionary = corpora.Dictionary(processed_data)
# 출현빈도가 적거나 자주 등장하는 단어는 제거
dictionary.filter_extremes(no_below=10, no_above=0.05)
corpus = [dictionary.doc2bow(text) for text in processed_data]
print('Number of unique tokens: %d' % len(dictionary))
print('Number of documents: %d' % len(corpus))
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
# 최적의 토픽 수 찾기 => 14개로 나옴
# find_optimal_number_of_topics(dictionary, corpus, processed_data)
# exit()
perplexity_logger = PerplexityMetric(corpus=corpus, logger='shell')
coherence_logger = CoherenceMetric(corpus=corpus, coherence="u_mass", logger='shell')
lda_model = LdaModel(corpus, id2word=dictionary, num_topics=14, passes=30, callbacks=[coherence_logger, perplexity_logger])
topics = lda_model.print_topics(num_words=5)
for topic in topics:
print(topic)
# Compute Coherence Score using c_v
coherence_model_lda = CoherenceModel(model=lda_model, texts=processed_data, dictionary=dictionary, coherence='c_v')
coherence_lda = coherence_model_lda.get_coherence()
print('\nCoherence Score (c_v): ', coherence_lda)
# Compute Coherence Score using UMass
coherence_model_lda = CoherenceModel(model=lda_model, texts=processed_data, dictionary=dictionary, coherence="u_mass")
coherence_lda = coherence_model_lda.get_coherence()
print('\nCoherence Score (u_mass): ', coherence_lda)
# 저장
pickle.dump(corpus, open('./data/lda/lda_corpus.pkl', 'wb'))
dictionary.save('./data/lda/lda_dictionary.gensim')
lda_model.save('./data/lda/lda_model.gensim')
# pyLDAvis html 저장
lda_visualization = pyLDAvis.gensim.prepare(lda_model, corpus, dictionary, sort_topics=False)
pyLDAvis.save_html(lda_visualization, './data/lda/독립유공자공적조서_lda.html')
pyLDAvis.show(lda_visualization)결과는 최종 c_v가 0.58이고 u_mass는 -4가 나오고 있다.

참고로 u_mass는 0에 가까울수록 완벽한 일관성을 가진다는 의미이고
c_v는 0과 1사이로 0.55 정도면 준수하다고 하는 것 같다.(어디서 봤는지 기억이 안남..)
https://datascienceplus.com/evaluation-of-topic-modeling-topic-coherence/
'ML&DL' 카테고리의 다른 글
| 임베딩 - GloVe (6) | 2020.08.25 |
|---|---|
| 임베딩 - FastText (한글 자소 분리) (0) | 2020.08.16 |
| mecab 사전 우선순위 조정 (3) | 2020.08.13 |
| 임베딩 - FastText (2) | 2020.08.13 |
| Word2Vec - 시각화 2 (1) | 2020.08.12 |
- Total
- Today
- Yesterday
- Knowledge Graph
- TopBraid Composer
- 지식 그래프
- TBC
- django
- cypher
- 트리플 변환
- 지식그래프
- neosemantics
- property graph
- 그래프 데이터베이스
- RDF
- 장고
- Thymeleaf
- Neo4j
- 트리플
- RDF 변환
- Linked Data
- sparql
- rdfox
- Ontology
- 스프링부트
- stardog
- 사이퍼
- LOD
- TDB
- networkx
- 온톨로지
- 타임리프
- pyvis
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |