
티스토리 뷰
이번에는 이전 글에서 생성한 Word2Vec의 결과를 시각화하여 보려고 한다.
PCA와 t-SNE을 통해 고차원 데이터를 차원 축소하고 시각화를 할 수 있다.
이들은 비지도 학습의 종류 중 하나인 비지도 변환의 일종으로 데이터를 새롭게 표현하여 사람이나 다른 머신러닝 알고리즘이 원래 데이터보다 쉽게 해석할 수 있도록 만드는 알고리즘이라고 할 수 있다.
차원 축소 분야에서 많이 사용하며 데이터를 구성하는 단위나 성분 찾기에도 사용한다.
PCA(주성분 분석)은 특성들이 통계적으로 상관관계가 없도록 데이터셋을 회전시키는 기술로서 특성들의 상관관계가 가장 큰 방향(분산이 가장 큰 방향)을 찾고 그 방향과 직각인 방향 중에서 가장 많은 정보를 담은 방향을 찾아낸다.
PCA는 주성분의 일부만 남기는 차원 축소 용도로 사용할 수 있다. 예시로 2차원 데이터셋에서 첫번째 주성분만 유지하고자 하면 1차원 데이터셋으로 차원이 감소한다. 그러나 단순히 원본 특성 중 하나만 남기는 것이 아니라 가장 유용한 방향을 찾아서 그 방향의 성분, 즉 첫 번째 주성분을 유지하는 것이다.
데이터를 산점도로 시각화 할 수 있다는 이점 떄문에 PCA가 종종 데이터 변환에 가장 먼저 시도해볼 만한 방법이지만
알고리즘의 태생상 유용성이 떨어진다.
매니폴드 학습 알고리즘이라고 하는 시각화 알고리즘들은 훨씬 복잡한 매핑을 만들어 더 나은 시각화를 제공하는데 특히 t-SNE 알고리즘을 아주 많이 사용한다.
매니폴드 학습 알고리즘은 그 목적이 시각화라 3개 이상의 특성을 뽑는 경우는 거의 없다.
t-SNE를 포함해서 일부 매니폴드 알고리즘들은 훈련 데이터를 새로운 표현으로 변환시키지만 새로운 데이터에는 적용하지 못한다.
t-SNE의 아이디어는 데이터 포인트 사이의 거리를 가장 잘 보존하는 2차원 표현을 찾는 것이다.
먼저 각 데이터 포인트를 2차원에 무작위로 표현한 후 원본 특성 공간에서 가까운 포인트는 가깝게, 멀리 떨어진 포인트는 멀어지게 만든다.
그럼 PCA와 t-SNE을 통해 임베딩 결과를 시각화 해보도록 한다.
코드
from sklearn.manifold import TSNE
from sklearn.decomposition import PCA
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
from gensim.models import KeyedVectors
# 그래프에서 마이너스 폰트 깨지는 문제에 대한 대처
mpl.rcParams['axes.unicode_minus'] = False
plt.rc('font', family='D2Coding')
def show_tsne():
tsne = TSNE(n_components=2)
X = tsne.fit_transform(X_show)
df = pd.DataFrame(X, index=vocab_show, columns=['x', 'y'])
fig = plt.figure()
fig.set_size_inches(30, 20)
ax = fig.add_subplot(1, 1, 1)
ax.scatter(df['x'], df['y'])
for word, pos in df.iterrows():
ax.annotate(word, pos, fontsize=10)
plt.xlabel("t-SNE 특성 0")
plt.ylabel("t-SNE 특성 1")
plt.show()
def show_pca():
# PCA 모델을 생성합니다
pca = PCA(n_components=2)
pca.fit(X_show)
# 처음 두 개의 주성분으로 숫자 데이터를 변환합니다
x_pca = pca.transform(X_show)
plt.figure(figsize=(30, 20))
plt.xlim(x_pca[:, 0].min(), x_pca[:, 0].max())
plt.ylim(x_pca[:, 1].min(), x_pca[:, 1].max())
for i in range(len(X_show)):
plt.text(x_pca[i, 0], x_pca[i, 1], str(vocab_show[i]),
fontdict={'weight': 'bold', 'size': 9})
plt.xlabel("첫 번째 주성분")
plt.ylabel("두 번째 주성분")
plt.show()
model_name = 'D:/Data/embedding/data/word-embeddings/word2vec/word2vec'
model = KeyedVectors.load_word2vec_format(model_name)
vocab = list(model.wv.vocab)
X = model[vocab]
# sz개의 단어에 대해서만 시각화
sz = 800
X_show = X[:sz,:]
vocab_show = vocab[:sz]
show_tsne()
show_pca()
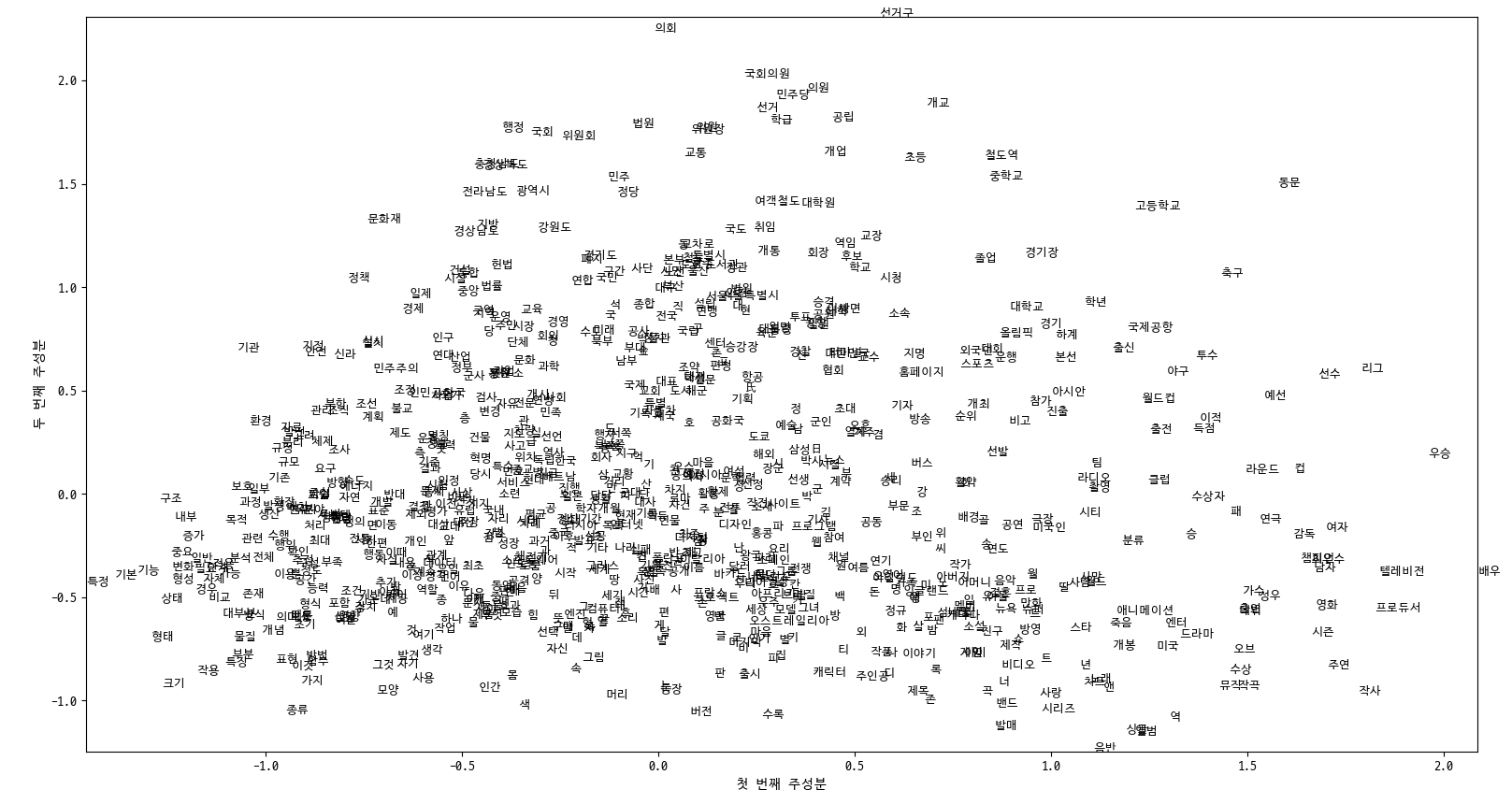
결과 (PCA)
결과 (t-SNE)
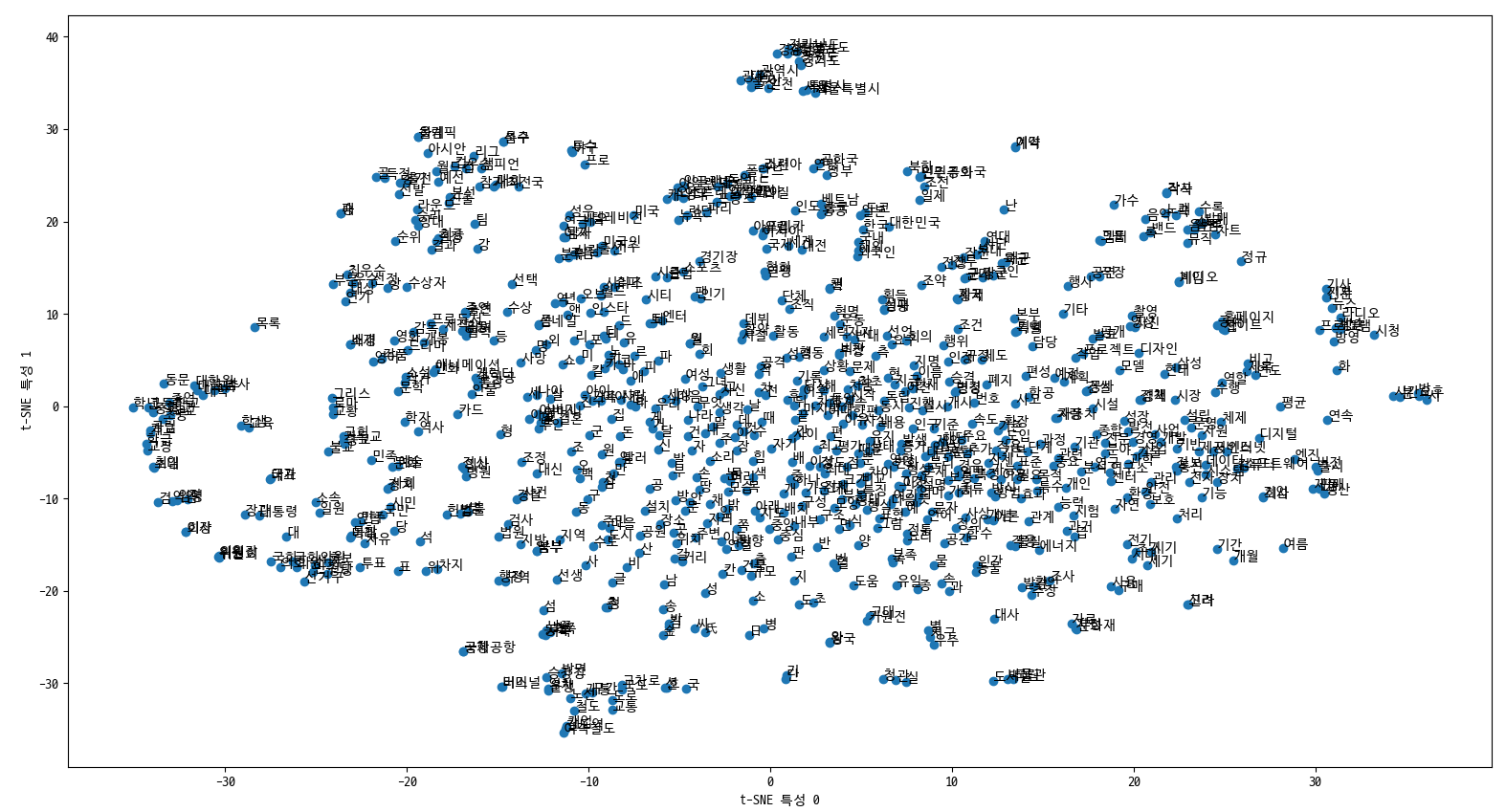
100 차원의 임베딩 결과를 2차원으로 시각화 한 결과들이다.
전체 데이터 중 800개만 보이도록 하였는데 그럼에도 잘 볼 수가 없다.
다음에는 https://projector.tensorflow.org/ 에서 시각화하여 보는 방법에 대해서 기록을 남기도록 하겠다.
참고서적
https://www.hanbit.co.kr/store/books/look.php?p_code=B6119391002
파이썬 라이브러리를 활용한 머신러닝
사이킷런 핵심 개발자에게 배우는 머신러닝 이론과 구현
www.hanbit.co.kr
참조
https://github.com/rickiepark/introduction_to_ml_with_python
'ML&DL' 카테고리의 다른 글
| 임베딩 - FastText (2) | 2020.08.13 |
|---|---|
| Word2Vec - 시각화 2 (1) | 2020.08.12 |
| 임베딩 - Word2Vec (5) | 2020.08.12 |
| 명사 추출 - 네이버 영화리뷰 (0) | 2020.08.11 |
| 데이터 전처리 - 네이버 영화리뷰 (0) | 2020.08.11 |
- Total
- Today
- Yesterday
- 지식그래프
- 지식 그래프
- 트리플
- networkx
- TopBraid Composer
- 그래프 데이터베이스
- property graph
- Linked Data
- stardog
- 스프링부트
- LOD
- rdfox
- sparql
- 온톨로지
- django
- Neo4j
- 타임리프
- Thymeleaf
- Knowledge Graph
- RDF
- pyvis
- RDF 변환
- 트리플 변환
- neosemantics
- cypher
- Ontology
- TBC
- 장고
- 사이퍼
- TDB
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |