
티스토리 뷰
지식그래프 생성
지식그래프 연재에서는 지식그래프를 구성하고 이를 활용하는 것까지 간단히 살펴보고자 합니다. 모든 활용을 다룰 수는 없지만 대략적으로 많이 사용하는 방법들에 대해서 다루려고 합니다.
첫번째 연재로는 지식을 구성하는 방법으로 데이터가 주어졌을 때 일반적인 데이터베이스 구성이 아니라 명시적인 방법과 그래프 표현으로 데이터를 구성하고 저장합니다.
지식이란 정보를 체계화하고 개념화한 것입니다. 우리가 사용하는 시스템 혹은 데이터들은 분류체계, 사전, 목록 등으로 구성되는 경우가 많습니다. 이러한 종류의 데이터는 단일 데이터베이스에 구축하고 특정 응용프로그램에서만 사용하기 보다는, 용어 목록을 정의하고 공유하여 사용함으로 중복의 문제, 관리 용이성, 동일한 정책적 표준 등의 이점을 얻을 수 있습니다.
지식 그래프를 구성하기 위해 사용하는 대부분의 기술과 표준은 시맨틱 웹의 산물로 구성될 수 있습니다. 이중에서도 RDF와 SKOS는 지식 그래프를 구성하는 기본이라고 할 수 있습니다. 용어 목록에 대한 표준적인 접근법으로 SKOS를 활용할 수 있습니다.
이번 글에서는 카테고리 분류체계를 지식 그래프로 생성하는 과정을 이야기 하고자 합니다.
데이터는 https://arxiv.org/category_taxonomy 에서 게시되어 있습니다.
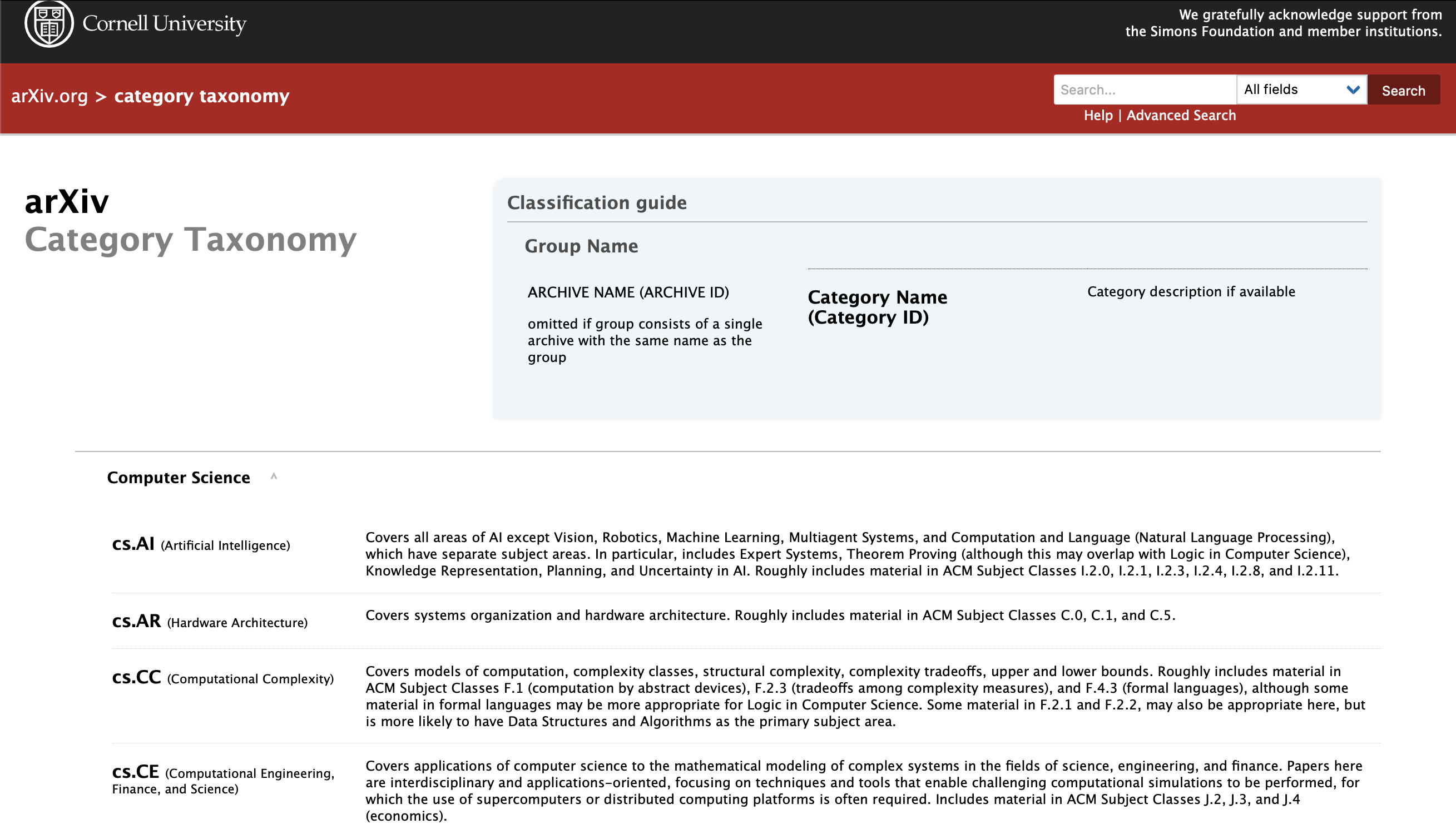
이 사이트에 게시된 내용을 엑셀로 전환하여 시작하도록 합니다.

위의 데이터를 응용 프로그램에서 사용하기 위해서 일반적으로 RDB의 테이블에 데이터를 적재하고 검색이 필요한 컬럼을 색인하고 사용합니다. 단일 응용 프로그램에서만 사용한다면 이러한 방식은 큰 문제없이 잘 동작합니다. 그런데 만약 다른 응용 프로그램에서 (데이터베이스도 다른 경우) 이 데이터를 사용하려고 한다거나 arxiv 카테고리 택소노미가 변경되었을 경우에는 어떻게 해야 할까요? 대부분 새롭게 데이터를 구성하거나 동일한 내용의 데이터를 다른 데이터베이스에 복제 구성을 합니다.
만약 이 데이터를 한 곳에서 제공해주고 이를 각각의 응용 프로그램들이 가져다 쓸 수 있다면 어떠할까요? 그리고 arxiv 카테고리 택소노미가 변경되었을 경우 이 한곳에서만 버전을 관리하며 업데이트를 해주고, 기존에 이 데이터를 사용하는 다른 프로그램들은 신경쓰지 않아도 된다면 어떠할까요?
이러한 접근방법은 데이터도 하나의 제품으로 생각하여 데이터를 가져다 쓰는 소비자는 세부 사항(관리 포인트 혹은 버전 등)은 잘 모르더라도 자신이 필요한 데이터를 가져다 쓸 수 있는 것과 같습니다. 제품에 대한 업그레이드 및 관리는 제품을 제공하는 곳에서 담당하는 것처럼 데이터도 데이터를 제공하는 주체가 데이터에 대한 책임을 가지고, 사용자는 해당 데이터를 가져다 쓰기만 하면 됩니다.
그렇다면 API 방식으로 데이터를 제공하는 것과 같은 것이 아니냐고 생각하실 수 있습니다. 데이터를 제공받아 사용하는 것은 같습니다만 API는 그 API를 설계한 사람 혹은 애플리케이션이 허용한 것만 가져갈 수 있습니다. 이는 애플리케이션 중심이라고도 볼 수 있습니다. 접근 방법을 애플리케이션과는 다른 데이터 중심으로 생각한다면 지식 그래프는 데이터를 제공하고 교환하는데 탁월한 기능을 제공하니다. 데이터 자체에 접근하여 데이터 자체를 제공받아 사용할 수 있습니다. 이와 유사하게 지식 그래프는 FAIR 데이터 원칙의 많은 부분을 지원합니다.
부연 설명이 길어졌는데 다시 arxiv 카테고리 택소노미 데이터로 돌아와 지식 그래프로 구성하도록 하겠습니다. 이 데이터는 데이터 자체로 사용이 가능하고 데이터가 가지고 있는 지식 그 자체를 표현하여 제공하기 위해 SKOS 형태로 구성하도록 하겠습니다. SKOS에 대한 보다 상세한 설명은 https://joyhong.tistory.com/15 을 참조하시면 좋을 것 같습니다. 혹은 공식 웹사이트 https://www.w3.org/2004/02/skos/ 에서 보다 많은 자료를 찾을 수 있습니다.
우선 주어진 데이터에 대한 개괄적인 스케치를 하였습니다. 데이터는 arxiv 카테고리 분류체계에 대한 것으로 크게 group, archive, category 로 구분되고 광의/협의 관계를 가지고 있습니다. 각각은 skos의 Concept으로 생성하고, Concept은 모두 ConceptScheme을 통해 어떤 개념체계인지를 명시합니다.
그리고 group에 대한 Concept들은 group 이라는 Collection의 member로 연결되고, archive에 대한 Concept들은 archive라는 Collection의 member로 연결됩니다. category도 동일합니다.
Concept의 광의/협의 관계는 skos의 broader/narrower 로 연결을 함으로서 그 의미를 명시합니다.

이 외에 각 Concept들이 가지는 속성인 prefLabel, notation, definition들을 생성합니다.
axt:cs.AI a skos:Concept ;
skos:broader axt:CS ;
skos:definition "Covers all areas of AI except Vision, Robotics, Machine Learning, Multiagent Systems, and Computation and Language (Natural Language Processing), which have separate subject areas. In particular, includes Expert Systems, Theorem Proving (although this may overlap with Logic in Computer Science), Knowledge Representation, Planning, and Uncertainty in AI. Roughly includes material in ACM Subject Classes I.2.0, I.2.1, I.2.3, I.2.4, I.2.8, and I.2.11." ;
skos:inScheme axs:v1 ;
skos:notation "cs.AI" ;
skos:prefLabel "Artificial Intelligence" .
axt:CS a skos:Concept ;
skos:broader axt:Computer_Science ;
skos:inScheme axs:v1 ;
skos:notation "CS" ;
skos:prefLabel "Computer Science" .
axt:Computer_Science a skos:Concept ;
skos:inScheme axs:v1 ;
skos:prefLabel "Computer Science" .
axs:v1 a skos:ConceptScheme ;
dc:description "This taxonomy was created by referring to <https://arxiv.org/category_taxonomy."> ;
dc:title "arxiv taxonomy version v1" .
axc:group a skos:Collection ;
rdfs:label "arxiv taxonomy group" ;
skos:member axt:Computer_Science,
axt:Economics,
axt:Electrical_Engineering_and_Systems_Science,
axt:Mathematics,
axt:Physics,
axt:Quantitative_Biology,
axt:Quantitative_Finance,
axt:Statistics .
위의 예시는 cs.AI에 대한 정보와 그 상위 Concept, 그리고 ConceptSchem, Collection에 대한 정보들만 일부분 나타내고 있습니다.
결과물은 이제 트리플 스토어에 저장하여 SPARQL을 통해 질의를 해 볼 수 있습니다.
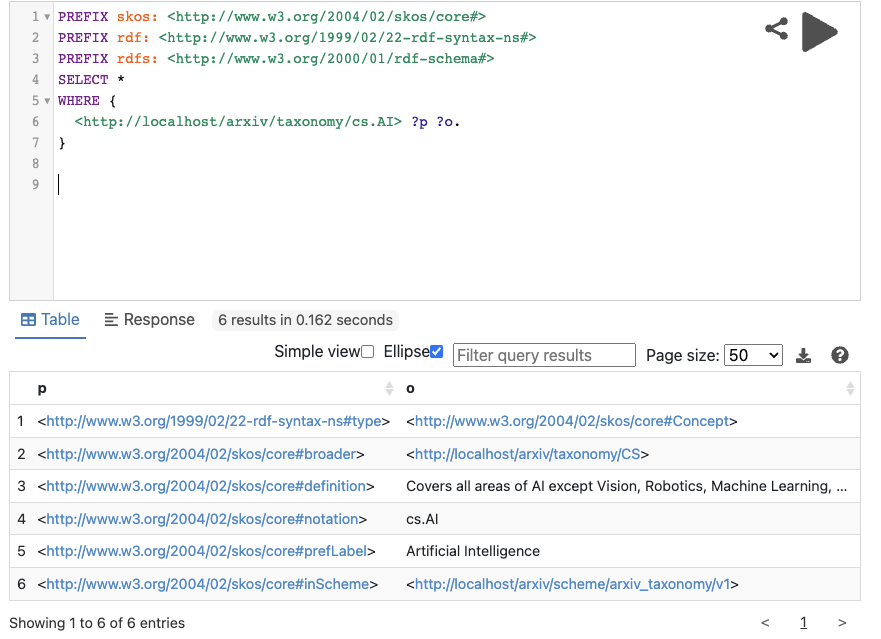
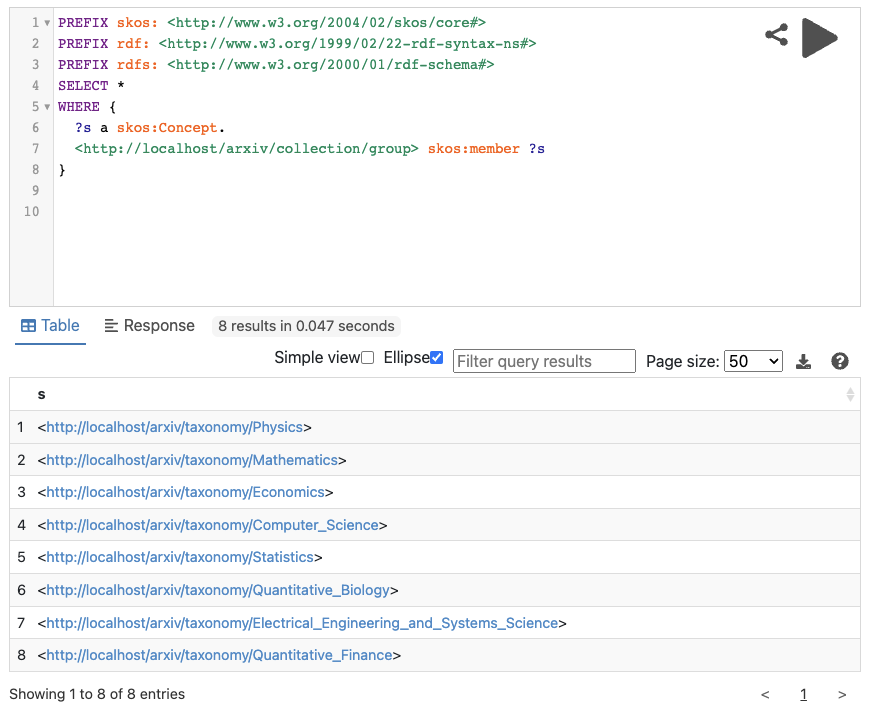
여기에서 더 나아가 SPARQL Endpoint를 추가하여 웹상에서 접근하여 해당 데이터를 가져가거나 SPARQL 질의를 통해 필요한 데이터를 가져가도록 할 수 있습니다. 하지만 이 연재에서는 이 부분은 구현하지 않을 것입니다.
여기까지는 실제 용어 목록을 지식 그래프 형태로 변환하여 생성하는 과정이였습니다. 그런데 만약 arxiv 분류체계에 업데이트가 발생하였다면 어떻게 대응을 하여야 할까요?
skos에서는 위에서 사용한 어휘 외에도 여러가지 어휘를 제공합니다. 먼저는 분류체계가 변경되면 버전이 달라지도록 관리가 필요합니다. 이를 위해 ConceptScheme 개념을 사용합니다. 위에서 만들었던 ConceptScheme은 v1 입니다. 분류체계가 변경되었기 때문에 v1.1 혹은 v2 와 같이 다른 ConceptScheme을 생성하여 변경이 된 분류체계를 inScheme으로 연결을 할 수 있습니다. 그리고 changeNote 어휘를 사용하여 변경된 내용을 기록할 수도 있습니다.
이미 기존의 데이터를 사용하고 있는 데이터 소비자는 기존에 사용하던 데이터를 계속 사용하면서도 새롭게 출시된 v2 분류체계도 동시에 사용이 가능해집니다. 만약 응용 프로그램에서 별도로 이 데이터를 적재하고 사용 중이였다면 데이터 업데이트 작업을 거쳐야 하지만 한곳에서 지식 그래프로 데이터를 제공하고 있기 때문에 데이터를 가져와 사용을 하면 됩니다.
이번 글에서는 체계화된 용어 목록을 SKOS 라는 것을 사용하여 지식 그래프로 생성하는 것을 간단히 보였습니다. 다음에는 개념화와 관련된 지식의 명시적인 표현으로 지식 그래프를 생성하는 것을 살펴보겠습니다.
끝.
'KnowledgeGraph' 카테고리의 다른 글
| [지식그래프] #3. 데이터 통합이 용이한 지식 그래프 (0) | 2022.08.27 |
|---|---|
| [지식그래프] #2. 개념화를 적용한 지식 그래프 (0) | 2022.08.26 |
| Knowledge Graph와 Data Fabric (0) | 2022.08.21 |
| Knowledge Graph : 지식 그래프 (0) | 2022.08.20 |
| 지식그래프를 활용한 사기 탐지 (0) | 2022.08.07 |
- Total
- Today
- Yesterday
- property graph
- TopBraid Composer
- sparql
- Neo4j
- 트리플 변환
- LOD
- 장고
- Ontology
- rdfox
- Linked Data
- stardog
- Knowledge Graph
- networkx
- 그래프 데이터베이스
- neosemantics
- RDF
- pyvis
- cypher
- TBC
- 타임리프
- RDF 변환
- 스프링부트
- 트리플
- 지식 그래프
- django
- Thymeleaf
- 지식그래프
- TDB
- 온톨로지
- 사이퍼
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |