
티스토리 뷰
지식그래프를 활용하는 사례들 중에 많은 언급이 되고 있는 사례는 사기 탐지로 보여진다.
사기 탐지와 같은 유형은 단일 데이터를 통해서는 사기와 같은 유형을 찾기가 어렵고,
많은 데이터들이 연결이 되어야 사기 유형의 관계를 보다 용이하게 찾아 낼 수 있다.
또한 시각화를 통해 어느 부분에서 어떤 데이터들이 사기 유형이 일어나는지 쉽게 파악이 가능하다.
이번 글에서는 다음의 사이트에서 제공하는 데이터를 활용하여 직접 사기탐지를 수행하는 맛보기를 해보고자 한다.
https://live.yworks.com/demos/complete/frauddetection/index.html
이 데이터의 주요 유형은 계정소유자, 신용카드, 은행지점, 지불, 연락처, 주소, 대출 등의 데이터를 제공하고 있으며, 특정 시점의 데이터가 아니라 enter_date, exit_date 를 통해 데이터의 유효한 날짜를 함께 제공하고 있다.
이 데이터의 주요 유형은 계정소유자, 신용카드, 은행지점, 지불, 연락처, 주소, 대출 등의 데이터를 제공하고 있으며, 특정 시점의 데이터가 아니라 enter_date, exit_date 를 통해 데이터의 유효한 날짜를 함께 제공하고 있다.

사전 준비 작업으로 위와 같은 엑셀의 데이터를 RDF 형태로 변경하여 트리플 스토어에 저장을 하였다.
반드시 RDF 형태로 변환하여 스토어에 저장할 필요는 없고 각자 필요에 따른 다른 선택도 얼마든지 가능하다.
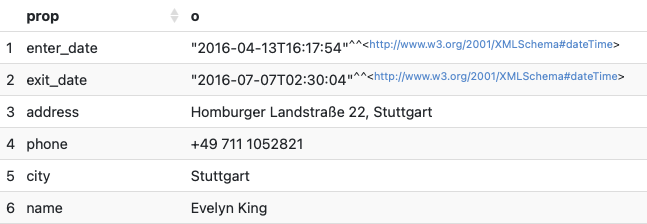
스토어에 잘 저장되어 있는지 확인하기 위해 이름이 Evelyn King 인 계정 소유자의 정보를 살펴보면 아래와 같다.
SELECT (afn:localname(?p) as ?prop) ?o
WHERE {
?s joy:name "Evelyn King".
?s ?p ?o.
?p a owl:DatatypeProperty.
}
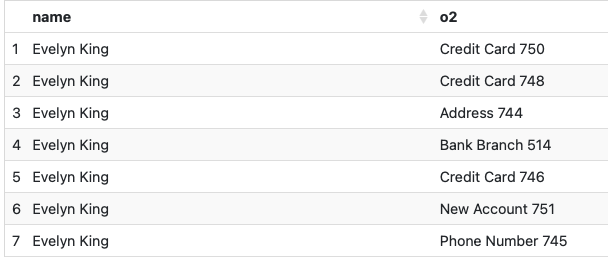
다음으로 Evelyn King 과 연결이 되는 주소, 신용카드, 새계정, 연락처 등등의 정보를 확인해보면 아래와 같다.
SELECT ?name ?o2
WHERE {
?s joy:name ?name.
FILTER(?name = "Evelyn King")
?s joy:link ?o.
?o rdfs:label ?o2.
}
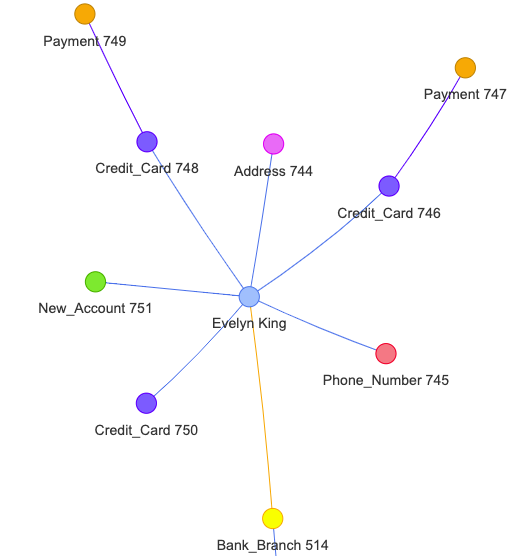
이러한 사항들을 그래프로 그리면 다음과 같은 형태가 나타난다.
서두에 링크한 데이터를 제공하는 측에서 이야기하는 사기 탐지의 시나리오는 합법적으로 은행에 상품을 요청하고, 일반고객과 같이 대출한 비용을 갚아 나가지만, 가짜 개인정보 (연락처나 주소)를 공유하는 경우 사기범의 유형이라고 제공한다.
따라서 실제로 그러한 데이터가 나오는지 살펴보겠다.
트리플스토어에 저장된 데이터를 가져와 그래프를 그려보면 아래와 같다.

사실 위와 같은 그래프는 흔히들 헤어볼이라고 표현하는 것처럼 그리 많은 의미가 없다.
뭔가 정보를 얻기 위한 후처리가 필요하다.
가만히 생각해보면 시나리오에서 언급했듯이
사기범은 대출과 같은 상품을 가입하고 정상인과 같이 일정기간 그 금액을 상환한다고 하였다.
그렇다면 특정 기간을 고려해야할 것 같기도 하다.
그래서 2016년 상반기만을 대상으로 다시 한번 살펴보면 아래와 같다.

처음에 비해 사이즈도 줄고 뭔가 고리가 보이는 것 같기도 하다.
그럼 이제 시나리오상에서 밝힌 바와 같이
계정소유자가 다른 계정소유자와 전화번호 또는 주소를 공유하는 패턴을 추출해볼 것이다.
우선 SPARQL 을 통해 전화번호 또는 주소를 공유하는 계정소유자를 찾아보았다.
시점은 간단히 2016년 이후의 시간으로 찾아보았다.
SELECT ?p1name ?mlabel ?p2name ?enter
WHERE {
?p1 joy:link ?m.
?p1 joy:name ?p1name.
?m rdfs:label ?mlabel.
?m a ?mtype.
VALUES ?mtype { joy:Address joy:Phone_Number}
?m joy:enter_date ?enter.
?m joy:exit_date ?exit.
?p2 joy:link ?m.
?p2 joy:name ?p2name.
FILTER(?p1!=?p2 && ?enter>=xsd:dateTime('2016-01-01T00:00:00'))
}
위와 같은 방법으로 2016년 상반기에 사기패턴이라 예상되는 데이터를 그래프 상에 마킹을 해보면 사기범들을 찾아볼 수 있을 것이다.

빨간색 굵은 선으로 그려진 부분이 사기범들이 개인정보를 공유하고 있다는 것을 나타낸다.
좀 더 확대를 해보면 아래와 같다.
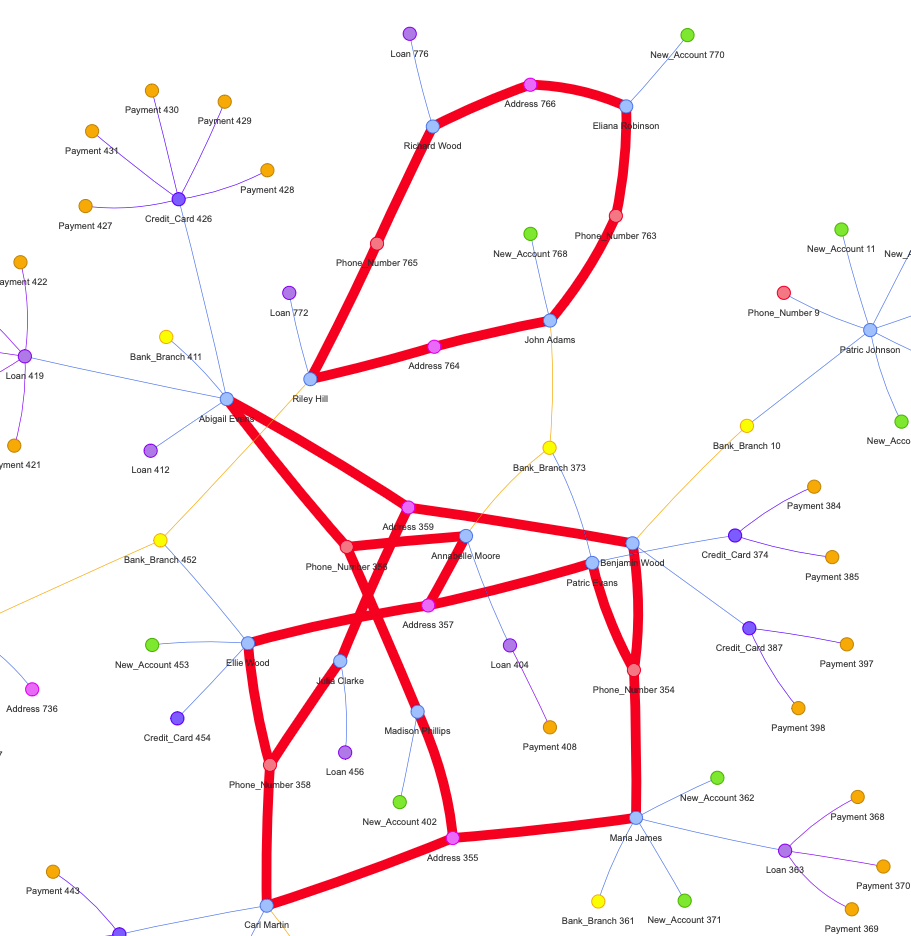
이와 같이 전형적인 사기 시나리오에 따라 주어진 데이터상에서 존재하는 사기를 탐지해 보았다.
위에 대한 실제 화면은 아래의 링크를 통해 확인이 가능하다.
위의 그래프에서는 노드의 색상은 노드의 타입에 따라 각각 구분되어 동일한 타입은 같은 색상으로 표현하고 있다.
동일한 데이터를 다른 시각화 도구를 활용하여서도 표현이 가능하다.
아래에서는 페이지랭크 알고리즘을 통한 중심성 계산과 레이블전파 알고리즘을 통한 커뮤니티 탐지를 함께 적용한 예시이다.
위와 같이 그냥 데이터를 보는 것보다 그래프 시각화를 통해 데이터를 살펴보면 몇가지 장점을 제공한다.
먼저 어디를 좀 더 살펴봐야할지 명확하게 알릴 수 있다. 또한 그래프 형태로 연결된 관계를 따라갈 수 있기 때문에 많은 데이터라 할지라도 편하게 탐색이 가능해진다. 관계가 연결이 되어 있기 때문에 다각적인 시야를 제공할 수 있다.
짧은 예시를 통해 이 글에서 설명하고자 한 내용은
데이터가 연결이 되어지면 그 안에서 어떠한 문제를 풀수 있는 정보를 찾을 수 있고,
이러한 정보를 시각화를 통해 쉽게 파악을 할 수 있다는 점을 보였다.
도메인이나 데이터에 따라 각각 도메인 지식 혹은 접근법이 달라지겠지만
가장 중요한 것은 데이터 사이에 연결이고, 이런 연결된 관계를 잘 표현해 낼 수 있는 것이 지식그래프 라는 것이다.
지식그래프에 대해서는 추후에 블로그에 작성해 볼 예정이다.
-끝-
'KnowledgeGraph' 카테고리의 다른 글
| [지식그래프] #3. 데이터 통합이 용이한 지식 그래프 (0) | 2022.08.27 |
|---|---|
| [지식그래프] #2. 개념화를 적용한 지식 그래프 (0) | 2022.08.26 |
| [지식그래프] #1. 체계화된 용어를 지식 그래프로.. (0) | 2022.08.24 |
| Knowledge Graph와 Data Fabric (0) | 2022.08.21 |
| Knowledge Graph : 지식 그래프 (0) | 2022.08.20 |
- Total
- Today
- Yesterday
- 그래프 데이터베이스
- Ontology
- 트리플
- neosemantics
- 타임리프
- Linked Data
- 지식 그래프
- TBC
- Thymeleaf
- LOD
- pyvis
- django
- TDB
- sparql
- stardog
- 온톨로지
- property graph
- 스프링부트
- RDF 변환
- rdfox
- Knowledge Graph
- Neo4j
- cypher
- 장고
- 트리플 변환
- TopBraid Composer
- RDF
- 사이퍼
- 지식그래프
- networkx
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |