
티스토리 뷰
임베딩 기법 중 Word2Vec을 활용하여 한국어를 대상으로 임베딩을 생성해보고자 한다.
대상이 되는 데이터는 지난 글에서 생성한
네이버 영화리뷰와 이와 더불어 KorQuAD, 한국어 위키백과 그리고 웹 크롤링을 통해 수집한 쇼핑몰의 사용자 리뷰데이터를 합하여 사용해 보았다.
준비한 데이터의 파일 크기는 약 690MB 이고, 라인수로는 약 67만 라인정도가 된다.
Word2Vec에 대한 설명은 다른 여러 블로그에서 충분히 설명하고 있기 때문에 쉽게 찾아볼 수 있다.
여기서는 gensim 이라는 패키지를 활용해 Word2Vec에 대한 코드를 작성한다.
코드
from gensim.models import Word2Vec
from gensim.models.callbacks import CallbackAny2Vec
from tqdm import tqdm
corpus_fname = 'D:/Data/embedding/data/tokenized/corpus_mecab.txt'
model_fname = 'D:/Data/embedding/data/word-embeddings/word2vec/word2vec'
class callback(CallbackAny2Vec):
"""Callback to print loss after each epoch."""
def __init__(self):
self.epoch = 0
self.loss_to_be_subed = 0
def on_epoch_end(self, model):
loss = model.get_latest_training_loss()
loss_now = loss - self.loss_to_be_subed
self.loss_to_be_subed = loss
print('Loss after epoch {}: {}'.format(self.epoch, loss_now))
self.epoch += 1
print('corpus 생성')
corpus = [sent.strip().split(" ") for sent in tqdm(open(corpus_fname, 'r', encoding='utf-8').readlines())]
print("학습 중")
model = Word2Vec(corpus, size=100, workers=4, sg=1, compute_loss=True, iter=5, callbacks=[callback()])
model.wv.save_word2vec_format(model_fname)
print('완료')실행 화면
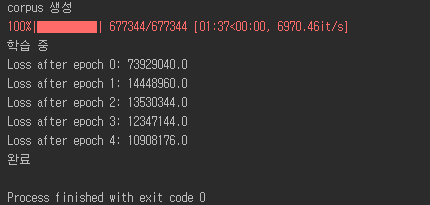
위 예시에서는 5번 반복을 하였는데 이 데이터상으로는 6~7번까지 해도 괜찮을 듯 싶다.
size는 100으로 설정하여 임베딩 차원수를 100으로 설정하였고
CPU 쓰레드 수는 4, sg=1을 통해 Skip-gram으로 설정하였다.
그리고 callbacks를 설정하여 epoch당 loss를 확인할 수 있도록 하였다.
그럼 생성된 임베딩 결과를 확인해보록 한다.
쉽게 접근할 수 있는 방법은 가장 유사한 단어나 두 단어의 유사도 계산 등이 있겠다.
코드1
from gensim.models import KeyedVectors
# 모델을 로딩하여 가장 유사한 단어를 출력
loaded_model = KeyedVectors.load_word2vec_format("D:/Data/embedding/data/word-embeddings/word2vec/word2vec") # 모델 로드
print(loaded_model.wv.vectors.shape)
print(loaded_model.wv.most_similar("최민식", topn=5))
print(loaded_model.wv.most_similar("남대문", topn=5))
print(loaded_model.wv.similarity("헐크", '아이언맨'))
print(loaded_model.wv.most_similar(positive=['어벤져스', '아이언맨'], negative=['스파이더맨'], topn=1))실행결과1

위 방법 외에도
https://github.com/ratsgo/embedding/blob/master/models/word_eval.py 의 코드를 참조하여 유사 단어 출력을 해 볼 수 있다. (이 사이트의 코드를 가져와 일부 수정하였습니다.)
코드2
from gensim.models import KeyedVectors
from konlpy.tag import Mecab
class WordEmbeddingSimilarWord:
def __init__(self, model_file, dim=100):
# self.model = KeyedVectors.load(model_file) # 모델 로드
self.model = KeyedVectors.load_word2vec_format(model_file) # 모델 로드
self.dim = dim
self.tokenizer = Mecab(dicpath='C:/mecab/mecab-ko-dic')
self.dictionary = self.load_dictionary(self.model)
def load_dictionary(self, model):
dictionary = []
for word in model.wv.index2word:
dictionary.append(word)
return dictionary
def get_sentence_vector(self, sentence):
tokens = self.tokenizer.nouns(sentence)
token_vecs = []
for token in tokens :
if token in self.dictionary :
token_vecs.append(token)
return token_vecs
def most_similar(self, sentence, topn=10):
token_vecs = self.get_sentence_vector(sentence)
return self.model.wv.most_similar(token_vecs, topn=topn)
wv = WordEmbeddingSimilarWord("D:/Data/embedding/data/word-embeddings/word2vec/word2vec", 100)
print(wv.most_similar("아이언맨과 배트맨", topn=5))
print(wv.most_similar("롯데월드", topn=5))
print(wv.most_similar("임시정부와 김구", topn=5))
실행결과2

코드2는 입력으로 문장을 넣으면 명사를 추출하여 명사 목록 list를 만들어 입력으로 넣고, 그 결과로 유사한 단어를 출력하도록 하였다.
다음에는 생성된 임베딩을 시각화하여 살펴보도록 하겠다.
'ML&DL' 카테고리의 다른 글
| Word2Vec - 시각화 2 (1) | 2020.08.12 |
|---|---|
| Word2Vec - 시각화(t-SNE, PCA) (2) | 2020.08.12 |
| 명사 추출 - 네이버 영화리뷰 (0) | 2020.08.11 |
| 데이터 전처리 - 네이버 영화리뷰 (0) | 2020.08.11 |
| pyeunjeon - koNLPy 스타일 mecab 래퍼 사용하기 (12) | 2020.07.24 |
- Total
- Today
- Yesterday
- stardog
- TBC
- Ontology
- neosemantics
- rdfox
- Neo4j
- cypher
- TDB
- 그래프 데이터베이스
- 타임리프
- 온톨로지
- RDF
- 사이퍼
- property graph
- TopBraid Composer
- 스프링부트
- 장고
- RDF 변환
- Thymeleaf
- django
- pyvis
- 트리플 변환
- Knowledge Graph
- 트리플
- 지식 그래프
- LOD
- 지식그래프
- Linked Data
- sparql
- networkx
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |