
티스토리 뷰
엑셀 형식의 데이터를 TBC에 불러와 활용하는 방법은 크게 3가지 정도가 있다.
1. TSV 형식으로 변경하여 온톨로지 모델에 반영하는 방법(혹은 모델 없이 RDF로 변경)
2. 엑셀 자체를 TBC로 읽어 기계적으로 RDF로 변경하는 방법
3. TBC에서 제공하는 스프레드시트 온톨로지 모델에 반영하는 방법
첫번째 방법은 이전 포스팅에서 이야기한 적이 있고
두번째 방법은 포스팅을 하지 않았는데 이유는 TBC에서 엑셀을 더블클릭하여 열면 semtable 이라는 형태에 맞춰 기계적으로 RDF로 변환되어 생성되기 때문이다.
이 때 엑셀의 시트명이 클래스명이 되고 A열의 데이터값이 subject로 만들어진다.
세번째 방법은 이제부터 이야기해보려고 한다.
스프레드시트 온톨로지는 TBC에서 제공하는 온톨로지모델 간단한 모델이다.
클래스는 워크북, 시트, 셀 3개로 구성되어 있고
프로퍼티는 10개의 프로퍼티로 구성되어 있다.
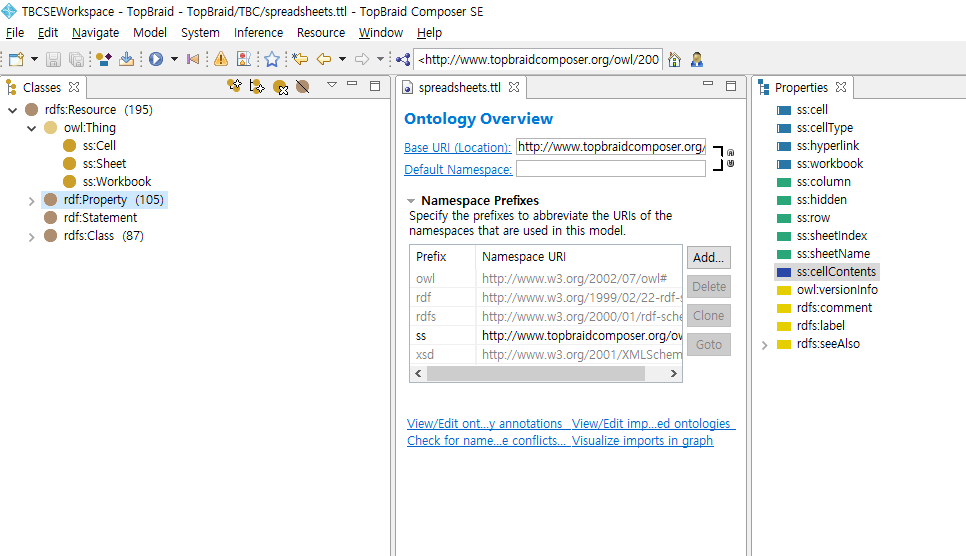
이 온톨로지는 엑셀의 데이터를 엑셀 그대로 담을 수 있는 모델인 것이다. 자세한 내용은 다시 살펴보기로 하고
엑셀데이터를 TBC로 불러와 스프레드시트 온톨로지로 담기 위해서는 예제로 사용할 엑셀 데이터가 필요하기 때문에
공공데이터포털(https://www.data.go.kr/)
공공데이터포털
국가에서 보유하고 있는 다양한 데이터를『공공데이터의 제공 및 이용 활성화에 관한 법률(제11956호)』에 따라 개방하여 국민들이 보다 쉽고 용이하게 공유•활용할 수 있도록 공공데이터(Dataset)와 Open API로 제공하는 사이트입니다.
www.data.go.kr
에서 제공하는 전국도서관표준데이터를 XLS 형태로 다운로드하여 준비하도록 한다.
URL은 https://www.data.go.kr/dataset/15013109/standard.do이다.
XLS 파일을 다운로드 받아 준비가 되면 TBC에서 프로젝트를 하나 생성하든 아니면 기존의 프로젝트를 그냥 사용하던지 정하여 프로젝트에 임포트를 한다.
이 글에서는 MyProject 라는 프로젝트에 임포트를 해보기로 한다.
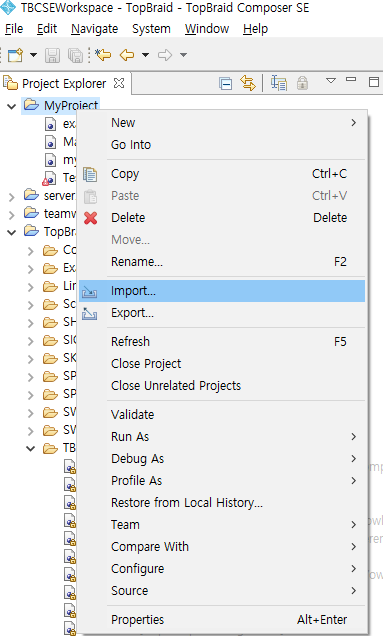
프로젝트를 하나 선택하고 마우스 우클릭을 한 뒤 Import를 선택한 뒤 나타나는 화면에서
TopBraid Composer > Import Excel File into Spreadsheet Ontology를 선택하고 Next 버튼을 누른다.

다음에 나오는 화면에서 Load Excel File 버튼을 눌러 공공데이터포털에서 다운받은 엑셀파일을 선택한다.
이 때 엑셀파일이 열려 있으면 다른 프로세스가 사용중이라며 에러가 발생하니 반드시 엑셀파일을 닫고 선택해야 한다.

엑셀 파일이 로드되면 Target RDF File name란에 자동으로 이름이 생성되어지고 그 밑에 Base URI 란에 적당한 Base URI를 입력한 뒤 Finish 버튼을 클릭한다.
정상적으로 임포트가 완료되면 선택했던 프로젝트 밑에 Target RDF File name에 입력된 파일명으로 하나의 RDF 파일이 생성되어 진다.

여기까지가 엑셀파일을 스프레드시트 온톨로지로 임포트 하는 과정 전부이다.
그럼 생성된 파일을 열어 살펴보도록 하자.
먼저 클래스영역을 살펴보면

워크북 클래스에 하나의 인스턴스, 시트 클래스에 하나의 인스턴스, 셀 클래스에 약 9만개의 인스턴스가 생성되어 있는 것을 볼 수 있다.
하나의 엑셀파일이라 하나의 워크북 인스턴스가 생성되어졌고, 그 엑셀에 하나의 워크시트가 있기 때문에 하나의 시트 클래스 인스턴스가 생성되어졌다.
그리고 마지막으로 셀 클래스의 인스턴스는 상당히 많은데 이는 셀 하나당 하나의 인스턴스가 생성되어지기 때문이다.
아무 셀 인스턴스를 하나 열어보면 다음과 같다.
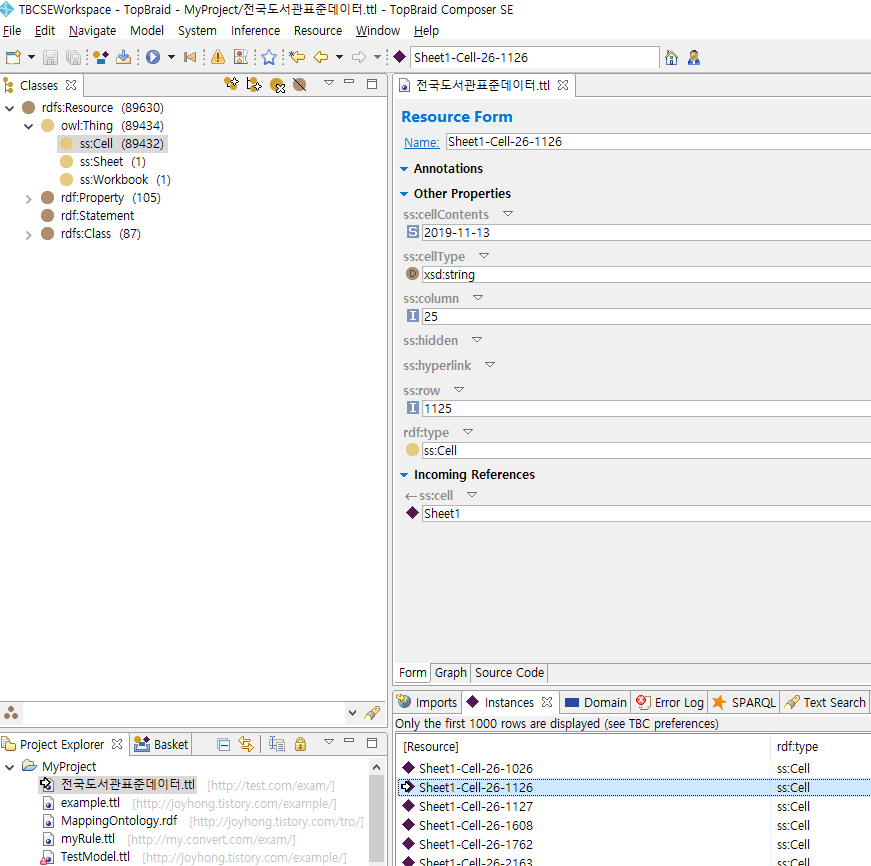
위의 예시에서 선택된 셀은 1125번 행의 25번째 컬럼인 셀이고, 그 셀의 값은 2019-11-13 이라는 것을 나타낸다.
정리하면 지금까지 설명한 엑셀 임포트 방식은 셀하나하나가 하나의 인스턴스로 생성되어지고 그 값을 가지고 있도록 변경된다는 것을 알 수 있다.
이제부터 어떻게 사용하느냐는 사용자가 선택해야 할 부분인데
여기서는 행 단위, 컬럼 단위로 살펴보는 SPARQL로 데이터를 확인해보도록 한다.
먼저 첫번째 행의 데이터들을 살펴보는 질의문을 실행시켜본다.
| SELECT * WHERE { ?s ss:row 0. ?s ss:cellContents ?data . ?s ss:column ?col. } order by ?col |
결과:
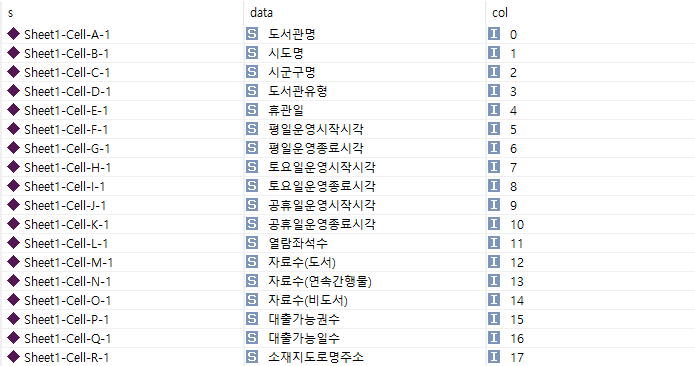
ss:row 프로퍼티로 연결된 object 값이 0 인 subject의 컨텐츠 내용과 컬럼번호를 가져와 컬럼번호로 정렬한 SPARQL 예시이다.
엑셀을 열어 확인해보면 첫번째 제목행이 내용과 동일한 정보가 나오는 것을 확인할 수 있다.
이번에는 도서관명 목록을 추출하도록 질의문을 실행시켜본다.
도서관명은 첫번째 컬럼에 들어가 있는 데이터값들이다.
| SELECT * WHERE { ?s ss:cellContents ?data . ?s ss:column 0. ?s ss:row ?row. } order by ?row |
결과:

여기서 엑셀의 1000번째 행의 도서관명을 알고 싶으면
| SELECT * WHERE { ?s ss:cellContents ?data . ?s ss:column 0. ?s ss:row 999. } |
결과:

이렇게 활용할 수도 있겠다.(너무 기초적인가..)
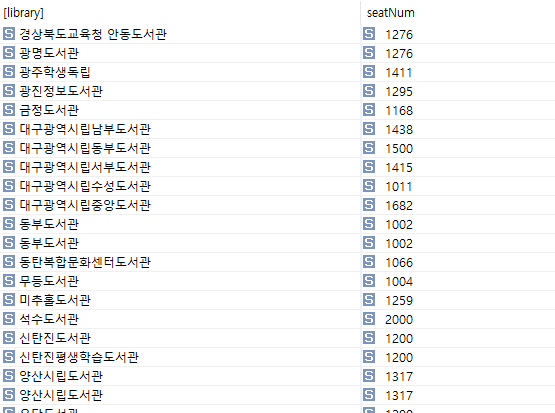
그럼 이번에는 열람좌석수가 1000석 이상인 도서관의 이름을 찾아보도록 한다.
이 엑셀에서 열람좌석수에 해당하는 컬럼 번호는 11이기 때문에 11번째 컬럼의 값이 1000 이상인 행번호를 가진 것을 먼저 찾고 그 다음에 0번째 컬럼의 값을 추출해내면 된다.
| SELECT ?library ?seatNum WHERE { ?s ss:cellContents ?seatNum . ?s ss:column 11. ?s ss:row ?row. filter( xsd:integer(?seatNum)>=1000) ?t ss:row ?row . ?t ss:column 0. ?t ss:cellContents ?library. } |
결과:
지금까지 위와 같이 이용할 수도 있다는 것을 포스팅하였고
다음에는 스프레드시트 온톨로지에 들어있는 트리플들을 내가 원하는 구조로 변경하여 파일로 만들어내는 방법에 대해서 살펴보도록 하겠다.
https://joyhong.tistory.com/89
N_14. CONSTRUCT 를 이용한 RDF 파일 생성
SPARQL 질의문에는 SELECT 이외에도 ASK, DESCRIBE, CONSTRUCT 구문이 있다. 지난 포스팅에서 엑셀 데이터를 스프레드시트 온톨로지로 임포트하는 방법에 대해 소개하였다. https://joyhong.tistory.com/88 N_13...
joyhong.tistory.com
'N:::만지작 거리기' 카테고리의 다른 글
| N_15. TBC에서 RDF 파일을 TDB에 임포트하기 (0) | 2019.12.11 |
|---|---|
| N_14. CONSTRUCT 를 이용한 RDF 파일 생성 (0) | 2019.12.10 |
| N_12. TSV 데이터를 RDF로 만들기 (0) | 2019.12.09 |
| N_11. 온톨로지 모델에 인스턴스 생성하기 - TSV (2) | 2019.12.08 |
| N_10. TopBraid Composer 사용법 (0) | 2019.12.08 |
- Total
- Today
- Yesterday
- django
- sparql
- 트리플
- RDF
- cypher
- 그래프 데이터베이스
- property graph
- Ontology
- 사이퍼
- 지식 그래프
- 장고
- 스프링부트
- LOD
- Linked Data
- pyvis
- neosemantics
- TBC
- networkx
- 트리플 변환
- stardog
- Knowledge Graph
- TDB
- 타임리프
- Neo4j
- 온톨로지
- TopBraid Composer
- RDF 변환
- rdfox
- Thymeleaf
- 지식그래프
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |