
티스토리 뷰
OCR은 Optical Character Recognition의 약자로 광학 문자 인식을 일컫는다.
이는 사람이 쓰거나 기계로 인쇄한 문자의 영상을 이미지 스캐너로 획득하여 기계가 읽을 수 있는 문자로 변환하는 것이다.
(참조: https://ko.wikipedia.org/wiki/%EA%B4%91%ED%95%99_%EB%AC%B8%EC%9E%90_%EC%9D%B8%EC%8B%9D)
OCR을 하기 위해서 사용하는 것 중 하나로 Tesseract가 있다.
테서렉트는 다양한 운영체제에서 사용할 수 있는 광학 문자 인식 엔진이다. 아파치 라이선스 2.0에 따르는 무료 소프트웨어이며 2006년 부터 구글이 개발을 후원하고 있다고 위키피디아에 나와 있다.
(참조: https://en.wikipedia.org/wiki/Tesseract_(software))
지난 2019년 10월에 테서렉트 5.0.0 버전이 업데이트 됨에 따라 그동안 사용중인 버전을 지우고 5.0 버전으로 새롭게 깔아보면서 기록을 남겨 본다.
테서렉트 OCR을 이용하는 주된 이유는 이미지에서 글자를 추출하고자 함이다. 커멘트라인에서 테서렉트를 이용하여 글자를 추출할 수도 있고, python 을 이용하여 원하는 바를 이룰 수 있겠다.
그 어떤 것을 하더라고 먼저 해야할 것은 테서렉트를 내 운영체제에 설치를 해야 한다.
설치하기 전에
Tesseract OCR 패키지는 OCR 엔진과 command line 프로그램을 포함하고 있다. Tesseract 4 버전부터 기존(Tesseract 3)의 문자 패턴 인식 기반의 엔진을 제공하면서, LSTM 기반의 OCR 엔진이 추가되었다. (https://github.com/tesseract-ocr/tesseract)
보다 자세한 내용과 설명은 위의 주소에서 확인을 해보자.
이미지에 있는 텍스트를 추출해보는 과정은
1. Tesseract-OCR 설치
2. Windows 환경변수 설정
3. Command line 테스트
4. Python에서 Tesseract 사용하기 (pytesseract)
으로 진행해보려고 한다.
Tesseract-OCR 설치에 대한 정보는 https://github.com/tesseract-ocr/tesseract/wiki 에서 찾을 수 있다.
1. Tesseract-OCR 설치
이번 테스트를 위해서 Windows 버전을 다운받아 설치한다.
Windows 버전은 https://github.com/UB-Mannheim/tesseract/wiki 에서 다운로드 받을 수 있다.
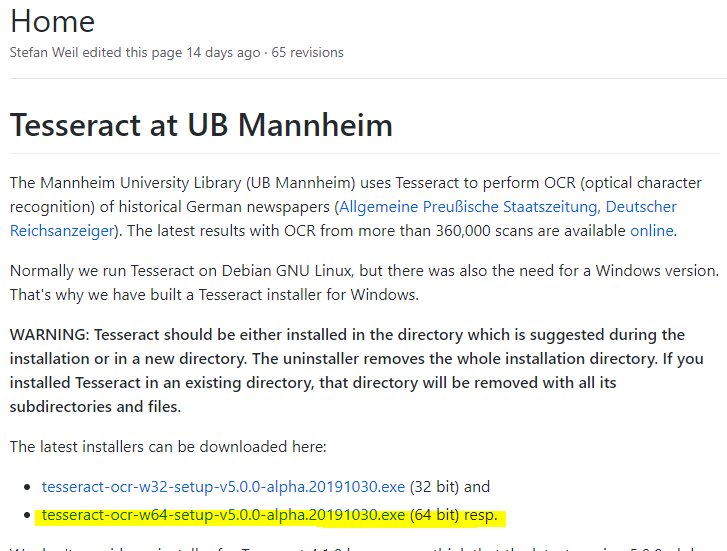
2019년 10월에 v5.0.0-alpha 버전이 최신으로 등록되었다.
최신 인스톨러인 tesseract-ocr-w64-setup-v5.0.0-alpha.20191030.exe 를 다운로드 받아 실행을 한다.
실행을 시키고 단계별로 Next를 누르다보면 컴포넌트를 선택하라는 창이 나온다
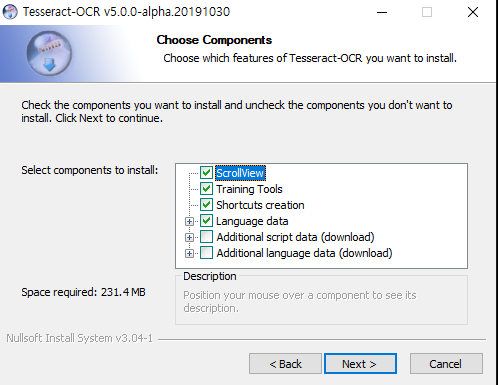
기본적으로 설치되는 언어데이터 이외에 다른 언어를 적용하기 위해서는 Additional language data를 선택해야 한다.
선택을 하게 되면 설치하는 과정에서 추가 언어 데이터를 다운로드 받는 과정을 거치게 된다. 따라서 필요에 따라 전체를 선택하든지, 필요한 언어 데이터만을 체크하든지 하면 된다.
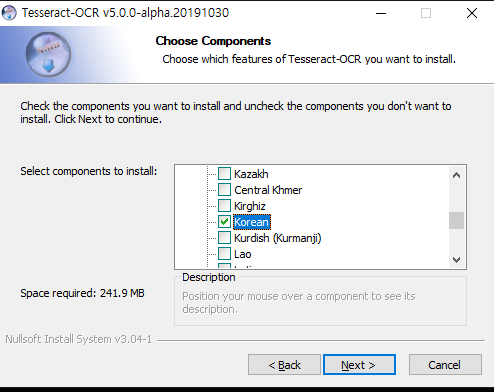
테스트 하려고 하는 이미지는 한글을 포함하고 있기 때문에 Korean만 선택한다.
만약 추후에 다른 언어가 필요하게 되면 테서렉트 깃헙에서 다운받아 사용하면 된다.
다운받은 언어데이터를 저장하는 위치는 설치를 하면서 지정하는 위치에 따라 종속되기 때문에 잠시 후에 보도록 한다.
선택을 하고 Next 버튼을 누르면 설치하려는 폴더를 묻는 창이 나온다. 디폴트로 나오는 폴더에 설치하든지 원하는 폴더로 변경하고 Next를 누른다. 이때 설치 폴더는 기억을 해두어야 한다. 왜냐하면 설치가 완료된 후 환경변수에서 Path를 추가해주어야 하기 때문이다.
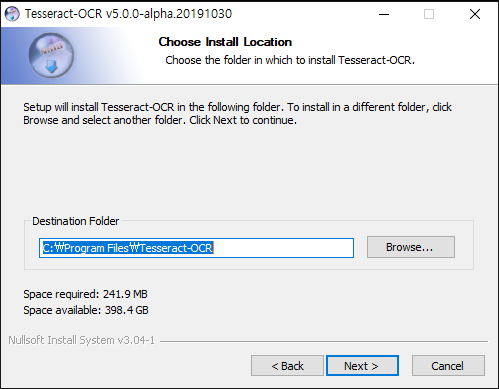
모든 과정을 마치고 최종 Install 버튼을 누르면 추가 스크립트 데이터와 언어 데이터를 다운로드 받는 과정과 함께 설치가 진행된다.
만약 추가 언어 데이터 전체를 선택하였다면 다운로드 과정을 한참동안 지켜보게 될 것이다.
설치가 완료 되었다.
설치과정에서 인스톨할 경로를 선택한 곳으로 가보면
위와 같이 생성된 결과를 볼 수 있다.
그 중에 tessdata 폴더에 들어가보면
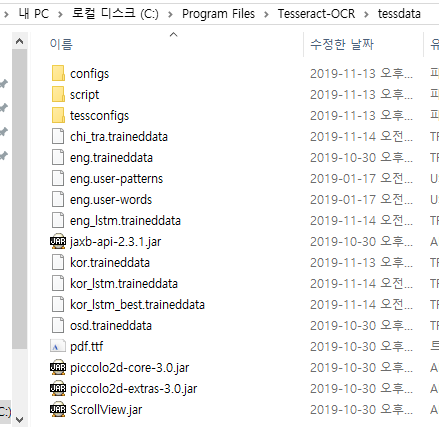
설치과정에서 선택한 언어데이터들이 들어가 있는 것을 확인할 수 있다. 위에서 언급한 바와 같이 다른 언어데이터가 필요할 경우 github에서 해당 언어데이터를 다운로드 받아 이곳에 저장하면 된다.
2. Windows 환경변수 설정
커맨드라인 명령을 통해 Tesseract를 사용하기 위해서는 먼저 [시스템 속성]에서 환경 변수를 등록해 주어야 한다.
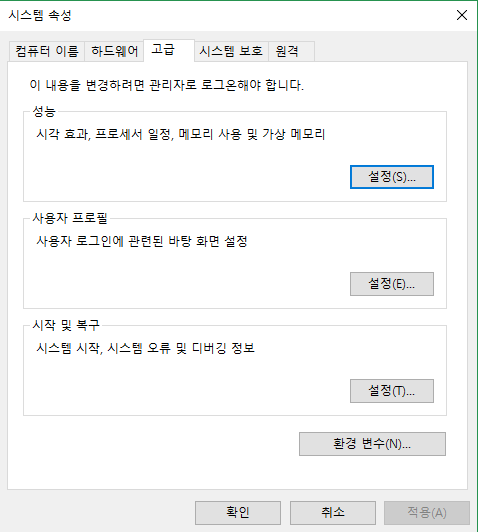
환경 변수를 선택하고 시스템 변수인 Path를 편집하여 Tesseract-OCR을 설치한 폴더를 추가한다.
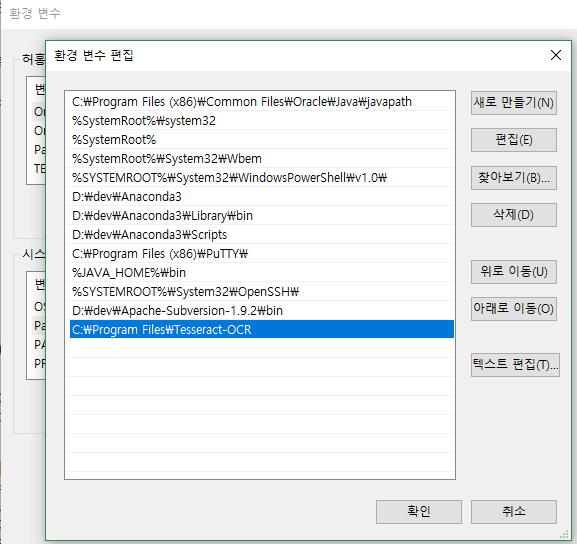
새로 만들기 버튼을 선택하여 위 그림과 같이 Tesseract-OCR 경로를 추가할 수 있다.
환경변수를 등록하였으면 cmd 창을 열러 tesseract 입력하여 확인을 해본다.

위와 같이 나오면 성공적으로 Tesseract-OCR 설치와 환경변수 등록이 완료된 것이다.
3. Command line 테스트
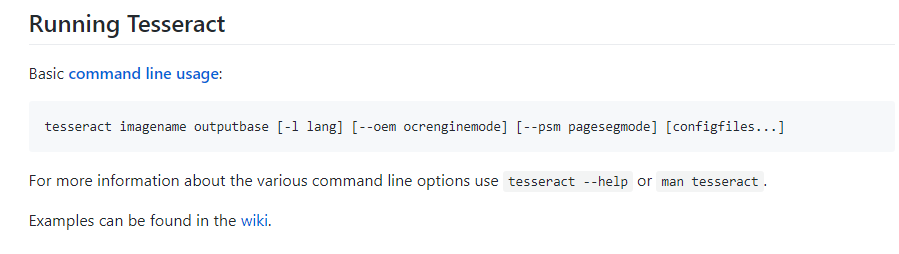
Tesseract에 대한 MD 에서 확인할 수 있는 사용법은 아래와 같다.
cmd창에서 테스트 하고자 하는 파일명을 입력하여 실행하면 이미지에서 글자를 추출하여 결과를 얻을 수 있다.
위와 같은 이미지를 입력하여 글자를 추출하고자 한다면 ( 위 파일이 sample.jpg 라 가정)
C:\Users>tesseract D:/Data/ocr/sample.jpg stdout
와 같이 실행하면 커멘트 창에서 바로 결과를 확인할 수 있다.
추출한 결과를 파일로 저장하고자 할 경우에는 stdout 대신에 저장할 파일 경로를 입력하면 된다.
C:\Users>tesseract D:/Data/ocr/sample.jpg D:/Data/ocr/sample_result
저장할 파일 경로는 확장자를 붙이지 않아도 자동으로 .txt가 만들어진다.
물론 위와 같이 실행하면 결과가 제대로 나오지 않는다.
모든 프로그램들이 그렇듯이 사용법을 알아볼 필요가 있다.
사용법은 Tesseract –help-extra 를 입력하면 아래와 같이 사용법을 볼 수 있다
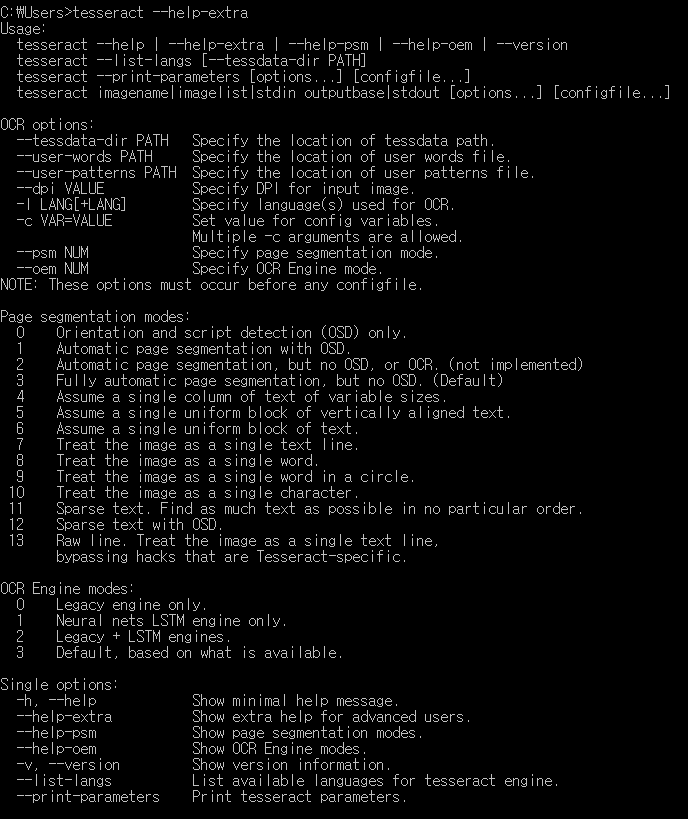
이제 추출하고자 하는 이미지의 글자가 한글이기 때문에 -l 옵션을 주어 한글을 인식하라고 지정해준다.
C:\Users>tesseract D:/Data/ocr/sample.jpg stdout -l kor

완벽하지는 않지만 한글이 제법 잘 인식이 되어서 결과로 나왔다. 그 중에는 영문도 있는데 영문은 인식이 되지 않은 것도 볼 수 있다. 이제 영문도 같이 인식을 시켜보고자 한다면
C:\Users>tesseract D:/Data/ocr/sample.jpg stdout -l kor+eng
와 같이 실행하면 된다.
계속 하다보면 느끼게 될 테지만 2개 이상의 언어를 추출하기 보다는 하나의 언어만 추출하는것이 더 좋은 결과를 가져오는 결과들을 볼 수 있다. 선택은 테스트 해보면서 해야할 것이다.
이번에는 사용법에 나와 있는 psm 옵션을 주면서 내가 가진 이미지 속에 텍스트를 어떤 방식으로 추출할 지 결정하면 된다.
C:\Users>tesseract D:/Data/ocr/sample.jpg stdout -l kor --psm 4
psm은 0부터 13까지 정수값 중에 하나를 선택하면 된다.
그리고 oem 옵션도 지정할 수 있다.
초반에 테서렉트 4부터는 LSTM 기반 OCR 엔진이 추가되었다고 했었는데 0부터 3까지 선택을 하면 된다.
이 때 LSTM 기반 엔진을 사용하려면 LSTM 모델을 업데이트한 언어 데이터를 다운 받아야 한다. 테서렉트를 설치하면서 받은 언어데이터에는 기본 데이터만 들어 있는 것으로 보여진다. 이 데이터로 LSTM 엔진을 사용하려고 하면 아래와 같은 에러가 발생한다.

이 문제를 해결하기 위해서 언어데이터를 https://github.com/tesseract-ocr/에서 다운로드 한다.
링크를 들어가면 위와 같이 LSTM 모델 데이터를 제공하고 있으며 kor 언어데이터를 다운로드받아 이름이 중복되지 않게 변경한 후 처음에 언급했던 저장 위치에 (Tesseract-OCR\tessdata) 저장하면 된다.
그 후 저장한 언어데이터명으로 변경하고 oem 값으로 1 또는 2를 입력하며 실행하면
C:\Users>tesseract D:/Data/ocr/sample.jpg stdout -l kor_lstm_best --psm 4 --oem 1

위와 같은 결과를 얻을 수 있다. LSTM 모델로 학습한 언어데이터를 쓰는게 반드시 좋은 결과를 가져다 주는 것은 아니지만 이렇게도 사용할 수 있다.
4. Python에서 Tesseract 사용하기 (pytesseract)
python에서 Tesseract를 사용하기 위해서는 pytesseract와 pillow를 설치해야 한다.
cmd창에서 pip로 설치를 한다.
>pip install pillow
>pip install pytesseract
설치가 끝나면 아래와 같은 코드를 통해 실행할 수 있다.
========================================
from PIL import Image
from pytesseract import *
filename = "D:/Data/ocr/sample.jpg"
image = Image.open(filename)
text = image_to_string(image, lang="kor")
with open("sample.txt", "w") as f:
f.write(text)
========================================
위의 코드를 ocr_tesseract.py로 저장 후 실행시키면 sample.txt로 결과가 생성된다.

- Total
- Today
- Yesterday
- rdfox
- 그래프 데이터베이스
- LOD
- TDB
- pyvis
- 스프링부트
- 온톨로지
- 트리플 변환
- django
- cypher
- Neo4j
- 트리플
- RDF
- Ontology
- 타임리프
- RDF 변환
- TopBraid Composer
- 사이퍼
- neosemantics
- networkx
- Thymeleaf
- 지식그래프
- Knowledge Graph
- sparql
- TBC
- 장고
- Linked Data
- property graph
- stardog
- 지식 그래프
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |