
티스토리 뷰
이번 연재글에서는 전통적인 방법론을 통해 온톨로지를 구축하고 지식그래프를 생성하는 것을 다룹니다.
그리고 지식그래프를 생성하는 과정에서 LLM 을 활용하는 방법에 대해서 다룹니다.
그리고 마지막으로 생성된 결과물에 대해 추론을 적용하여 활용도를 증가시키는 것에 대해 다룹니다.
이전 [#3 - LLM을 활용한 지식그래프 구축]에서는 학술논문의 초록에서 언급하는 주요한 용어들과 그 용어의 타입을 LLM을 활용함으로 자동으로 추출하고 이를 그래프 구조로 생성하였습니다. 이를 통해 학술논문에 대해 파악할 수 있는 더 많은 정보를 획득할 수 있었습니다.
이번글에서는 이를 좀더 확장하여 LLM을 통해 추출한 EntityNode의 타입인 EntityType에 대해 일반적인 계층 분류를 시도합니다.
EntityType을 통해 해당 논문이 숙소, 공항, 시설 등에 대해 언급하고 있다는 정보를 파악할 수 있게 되었지만, 특정 항목들에 대해 일일히 파악하기가 쉽지 않을 수 있습니다. 따라서 숙소, 공항, 시설 등이 일반적인 개념으로 "건물" 이라는 분류를 하게 되면, 건물에 대해 언급하는 모든 논문을 쉽게 찾아낼 수 있습니다. 더 나아가 건물을 객체(Object)라고 상위개념을 분류하게 되면 좀 더 추상화를 할 수 있습니다.
이런 방식으로 분류를 하게 되면 다음과 같이 일반화된 계층을 획득할 수 있게 됩니다.
| 1 depth | 2 depth | 3 depth | 4 depth |
| Entity | |||
| Organization | |||
| Company | |||
| Institution | |||
| Location | |||
| Country | |||
| Place | |||
| Object | |||
| Building | |||
| Accommodation | |||
| Airport |
이러한 데이터를 획득하기 위해 LLM에 EntityType의 목록을 제공하고 LLM이 자동으로 계층 분류를 하도록 요청하게 됩니다.
그 결과로 총 4depth의 분류체계를 획득하였고, 각각의 EntityType이 분류체계를 가지게 되었습니다.

이렇게 획득한 정보는 분류체계를 잘 표현할 수 있는 SKOS를 활용하여 지식그래프로 생성이 가능합니다. SKOS는 이 글에서 짧게 다루고 있으니 참고해 볼 수 있습니다.
SKOS를 통해 분류체계를 표현할 때 하위 depth에서 상위 depth로의 연결만 broader로 표현하였고, depth2와 depth3는 각각 Collection을 하나씩 생성하여 member 관계로 생성하게 됩니다. 이는 각 depth별로 같은 depth의 컨셉을 찾기 위한 목적으로 Collection 을 통해 생성하도록 합니다.
# 그래프 생성
g = Graph()
# namespace 바인딩
ONT = Namespace('http://joyhong.tistory.com/ontology/')
SKON = Namespace('http://joyhong.tistory.com/skos/')
OWL = Namespace('http://www.w3.org/2002/07/owl#')
SCHEMA = Namespace("http://schema.org/")
g.bind("rs", RS)
g.bind("ont", ONT)
g.bind("skon", SKON)
g.bind("schema", SCHEMA)
g.bind("foaf", FOAF)
g.bind("skos", SKOS)
g.bind("dcterms", DCTERMS)
g.bind("dc", DC)
g.add((URIRef(SKON+"collection_Depth2"), RDF.type, SKOS.Collection))
g.add((URIRef(SKON+"collection_Depth3"), RDF.type, SKOS.Collection))
for eh in eh_df.itertuples():
d1 = URIRef(SKON+eh.depth1.replace(" ", ""))
g.add((d1, RDF.type, SKOS.Concept))
g.add((d1, SKOS.prefLabel, Literal(eh.depth1_name)))
g.add((d1, RDFS.label, Literal(eh.depth1_name)))
g.add((d1, SKOS.note, Literal("Automatically classified using llm")))
entity_type = eh.depth1
if eh.depth2 != "":
d2 = URIRef(SKON+eh.depth2.replace(" ", ""))
g.add((d2, RDF.type, SKOS.Concept))
g.add((d2, SKOS.broader, d1))
g.add((d2, SKOS.prefLabel, Literal(eh.depth2_name)))
g.add((d2, RDFS.label, Literal(eh.depth2_name)))
g.add((d2, SKOS.note, Literal("Automatically classified using llm")))
g.add((URIRef(SKON+"collection_Depth2"), SKOS.member, d2))
entity_type = eh.depth2
if eh.depth3 != "":
d3 = URIRef(SKON+eh.depth3.replace(" ", ""))
g.add((d3, RDF.type, SKOS.Concept))
g.add((d3, SKOS.broader, d2))
g.add((d3, SKOS.prefLabel, Literal(eh.depth3_name)))
g.add((d3, RDFS.label, Literal(eh.depth3_name)))
g.add((d3, SKOS.note, Literal("Automatically classified using llm")))
g.add((URIRef(SKON+"collection_Depth3"), SKOS.member, d3))
entity_type = eh.depth3
if eh.depth4 != "":
d4 = URIRef(SKON+eh.depth4.replace(" ", ""))
g.add((d4, RDF.type, SKOS.Concept))
g.add((d4, SKOS.broader, d3))
g.add((d4, SKOS.prefLabel, Literal(eh.depth4_name)))
g.add((d4, RDFS.label, Literal(eh.depth4_name)))
g.add((d4, SKOS.note, Literal("Automatically classified using llm")))
entity_type = eh.depth4
try:
g.add((URIRef(RS+'entityType_'+str(types_idx.index(entity_type))), DCTERMS.subject, URIRef(SKON+entity_type.replace(" ", ""))))
except Exception as e:
print(e)
g.serialize("./uam_entity_skos.ttl", format='turtle')
위와 같이 파이썬 언어로 간단히 turtle 형식으로 파일을 생성하고, 이전 글에서와 같이 RDFox에 데이터를 로딩합니다.
이 때도 마찬가지로 named graph를 사용하여 기존의 데이터와 다른 분리된 영역에 저장을 하게 됩니다. (반드시 분리해야 하는 것은 아닙니다.)
지금까지 저장한 named graph를 살펴보면 각각의 결과물을 다르게 저장하였습니다. 지속적으로 언급하였지만 SPARQL을 통해 개별적인 named graph 안의 것만 조회하던지 다른 것들을 합쳐서 조회하던지 모두가 가능합니다.
지금 로딩한 결과물이 잘 로딩되었는지와 Concept과 EntityType 연결을 확인하기 위해 SPARQL을 생성하여 결과를 확인해보면 아래와 같이 확인이 가능합니다.
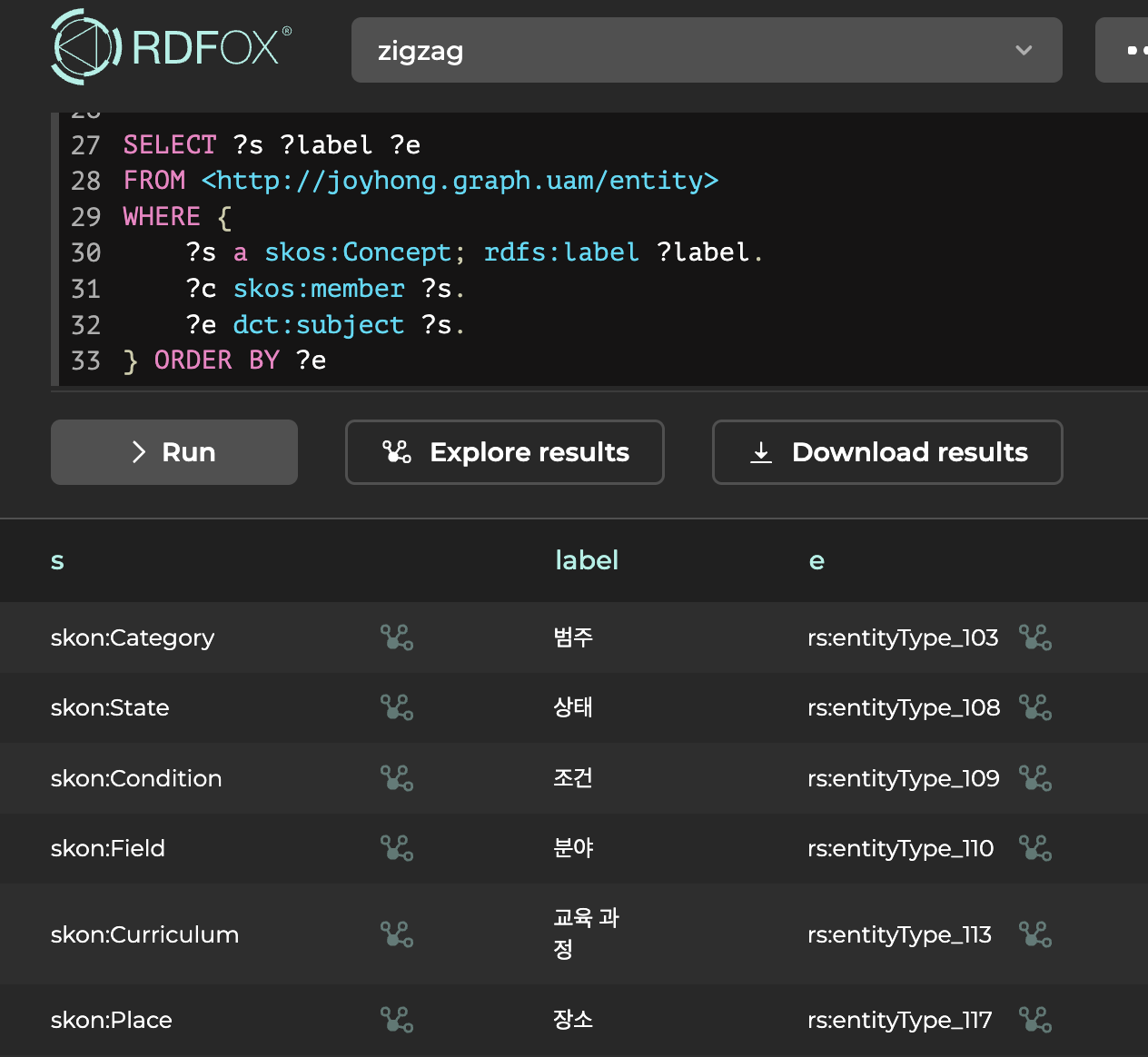
그럼 이번에는 모든 named graph로부터 정보를 추출하기 위해
"어떤 논문에서 다루고 있는 용어의 개념이 어떠한 분류체계에 속하며, 그 분류체계가 3번째 depth 집합들 중에 하나인 정보" 를 찾는 SPARQL을 생성해보도록 하겠습니다.
SELECT ?a ?articleName (GROUP_CONCAT (distinct ?keyword; SEPARATOR=" | ") as ?kwd)
(GROUP_CONCAT (distinct str(?concept) ; SEPARATOR=" | ") as ?cc)
(GROUP_CONCAT (distinct ?label; SEPARATOR=" | ") as ?conceptLabel)
FROM <http://joyhong.graph.uam/extracted>
FROM <http://joyhong.graph.uam/entity>
FROM <http://joyhong.graph.uam/basic>
FROM <http://joyhong.graph.uam/keyword>
WHERE {
{
SELECT distinct ?a ?y ?articleName ?keyword
WHERE {
?s ont:entityType ?y.
?s ont:mentionedBy ?a.
?a rdfs:label ?articleName .
?s rdfs:label ?keyword.
}
}
?y dcterms:subject ?ent.
?ent skos:broader+ ?concept.
skon:collection_Depth3 skos:member ?concept .
?concept skos:prefLabel ?label.
}
GROUP BY ?a ?articleNameFROM 절을 통해 사용하고자 하는 named graph를 명시하고 property 관계에 따라 찾고자 하는 질의를 생성하였습니다.
결과를 보면 위 조건에 맞는 논문과 분류체계를 찾아서 반환하는 것을 확인할 수 있습니다.
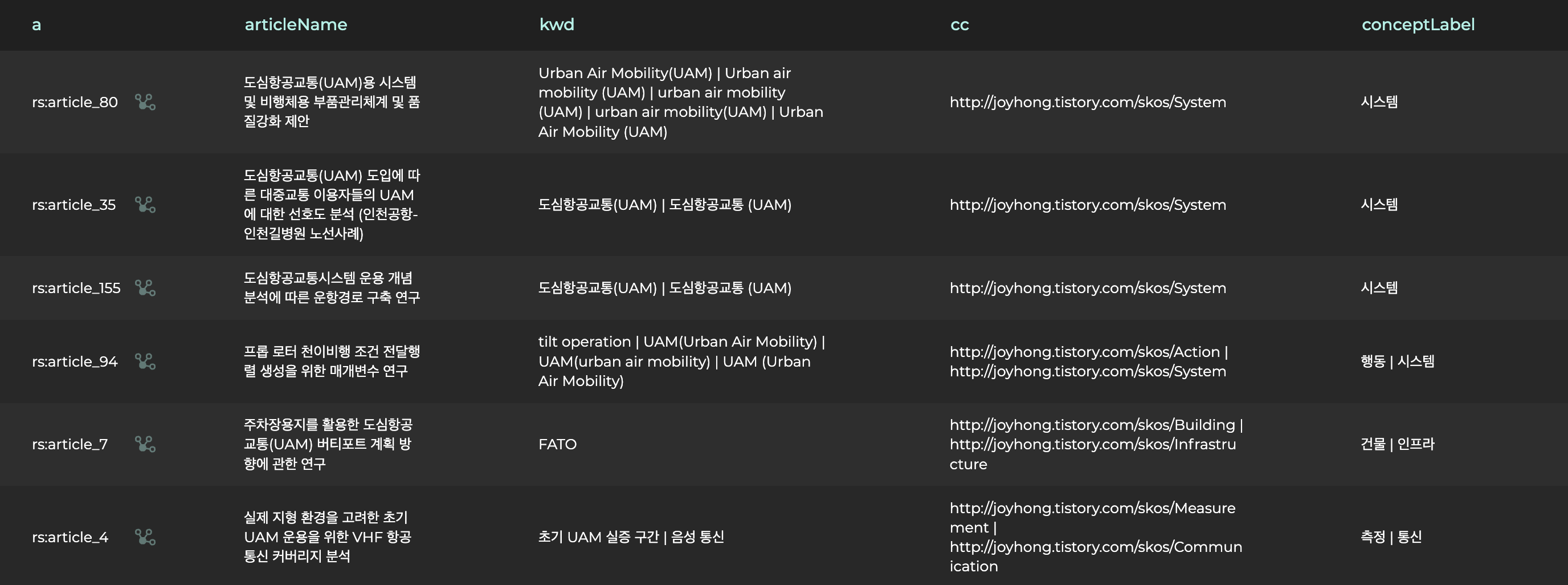
이번 글에서는 LLM을 활용하여 주어진 용어들을 일반화된 계층 분류로 생성하고 이를 지식그래프에 반영하여 추상화된 레벨에서 정보를 구성하는 과정을 간략히 보였습니다.
지식그래프를 구축하는 과정에서 정보를 확장하거나 위와 같이 분류가 필요할 때 LLM의 파워를 충분히 활용할 수 있는 것을 알 수 있습니다. 물론 항상 정확한 결과를 제공하는 것이 아니기 때문에 결과에 대한 검증과 신중한 판단이 필요할 것입니다.
그리고 점차적으로 확장된 정보를 하나의 SPARQL 을 통해 정보를 획득하고 조회하는 것을 보였습니다.
그러나 마지막에 조회한 SPARQL과 같이 조금 복잡한 쿼리문을 생성해야 한다면 쿼리 언어에 익숙하지 사람에게는 다소 어렵게 느껴질 수 있습니다. 따라서 다음 글에서는 이를 보완할 수 있는 기능에 대해 다루어보도록 하겠습니다.
-끝-
'KnowledgeGraph' 카테고리의 다른 글
| 두통 온톨로지 구축과 RDFox Datalog를 이용한 추론 (2) | 2024.10.10 |
|---|---|
| 지식그래프, LLM 그리고 Reasoning #5 - 추론 (2) | 2024.08.02 |
| 지식그래프, LLM 그리고 Reasoning #3 - LLM을 활용한 지식그래프 구축 (0) | 2024.07.31 |
| 지식그래프, LLM 그리고 Reasoning #2 - 키워드 구축 (0) | 2024.07.31 |
| 지식그래프, LLM 그리고 Reasoning #1 - 기본 지식그래프 구축 (0) | 2024.07.31 |
- Total
- Today
- Yesterday
- 그래프 데이터베이스
- sparql
- networkx
- neosemantics
- property graph
- 트리플
- 트리플 변환
- RDF 변환
- 지식 그래프
- rdfox
- Neo4j
- TBC
- LOD
- Linked Data
- Thymeleaf
- pyvis
- 타임리프
- 지식그래프
- django
- 스프링부트
- TopBraid Composer
- 온톨로지
- 장고
- Ontology
- cypher
- Knowledge Graph
- RDF
- 사이퍼
- stardog
- TDB
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |