
티스토리 뷰
그래프저장소 중인 하나인 Stardog을 활용하여 데이터를 저장해 두었다면
SPARQL Endpoint를 통해 다양한 검색,질의등을 수행할 수 있다.
이번 글은 Stardog에서 지원하는 엔드포인트를 통해 검색을 하고 그 결과를 테이블 형태로 가져오는 예시를 게시하려고 한다.
쥬피터 노트북을 통해 간단한 코드를 만드는데
여기서 활용하는 라이브러리는 pystardog, panel 이기 때문에 설치를 먼저 진행해야 한다.
pip install panel
pip install pystardog
In [1]:
import stardog
import pandas as pd
import io
import panel as pn
pn.extension('tabulator')
Endpoint 연결을 위한 설정(예시:Stardog)¶
In [2]:
conn_details = {
'endpoint': 'https://---yours---.stardog.cloud:5820',
'username': 'joy',
'password': 'password'
}
검색 쿼리¶
In [3]:
def search(keyword):
query = """
PREFIX ont: <http://localhost/ontology/>
SELECT (SAMPLE(?label) as ?label) (GROUP_CONCAT(distinct ?genre_;SEPARATOR=',') as ?genre)
(SAMPLE(?dirtlabel) as ?director) (SAMPLE(?open) as ?open) (SAMPLE(?mt) as ?movieType)
WHERE {
# FILTER(?s=<http://localhost/resource/movie_20000068>)
?s rdfs:label ?label .
?label <tag:stardog:api:property:textMatch> "%s" .
?s ont:dateOfOpen ?open.
?s ont:genre ?genre_.
?s ont:director ?dirt.
?dirt rdfs:label ?dirtlabel.
?s ont:movieType ?mt.
} GROUP BY ?s
LIMIT 10
""" % (keyword)
with stardog.Connection('Movie', **conn_details) as conn:
csv_results = conn.select(query, content_type='text/csv')
df = pd.read_csv(io.BytesIO(csv_results))
return df
검색¶
In [4]:
df = search(input())
select_table = pn.widgets.Tabulator(df)
select_table
Out[4]:
In [ ]:
실행 결과는 아래와 같이 테이블 형태로 결과를 확인할 수 있다.
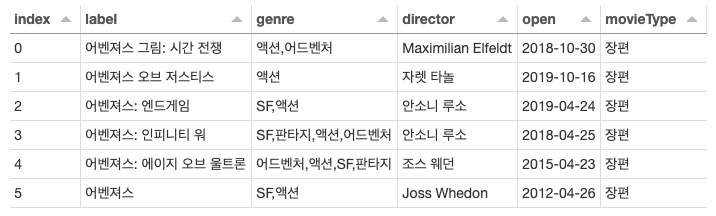
이를 활용하여 그래프 시각화 부분을 연동하게 되면
아래의 영상과 같은 방법으로도 활용이 가능한다.

'N:::만지작 거리기' 카테고리의 다른 글
| 팔란티어 Platform overview (0) | 2025.02.05 |
|---|---|
| 텍스트를 그래프로 파악하기 (1) | 2023.10.06 |
| 배우들간의 공동 출연 네트워크 (0) | 2023.02.12 |
| 영화 데이터 살펴보기 with Stardog-studio (0) | 2023.02.04 |
| 10분만에 지식그래프 만들기 with Stardog (0) | 2023.01.28 |
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
TAG
- Knowledge Graph
- Ontology
- TopBraid Composer
- Thymeleaf
- 지식 그래프
- 지식그래프
- 사이퍼
- pyvis
- LOD
- sparql
- TDB
- Neo4j
- 온톨로지
- TBC
- neosemantics
- 트리플
- RDF 변환
- 장고
- cypher
- rdfox
- 트리플 변환
- Linked Data
- 타임리프
- networkx
- RDF
- 그래프 데이터베이스
- 스프링부트
- property graph
- django
- stardog
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
글 보관함