
지식그래프, LLM 그리고 Reasoning #1 - 기본 지식그래프 구축
이번 연재글에서는 전통적인 방법론을 통해 온톨로지를 구축하고 지식그래프를 생성하는 것을 다룹니다.
그리고 지식그래프를 생성하는 과정에서 LLM 을 활용하는 방법에 대해서 다룹니다.
그리고 마지막으로 생성된 결과물에 대해 추론을 적용하여 활용도를 증가시키는 것에 대해 다룹니다.
사용하는 데이터는 KCI, Google Scholar 등에서 2010년부터 2024년까지 발행된 항공 관련 논문데이터를 수집한 데이터셋을 활용합니다. 데이터셋의 양은 총 213건이며 주로 학술논문, 학술지명, 키워드, 저자, 발행연도, 주제분야 등의 정보를 가지고 있습니다. 이 데이터셋은 지그재그 모임에서 활동하는 이시연 님이 제공한 데이터셋입니다.

이 글에서 사용하는 그래프데이터베이스는 RDFox 입니다. RDFox는 Oxford Semantic Technologies 에서 제공하는 지식그래프 및 추론 엔진을 제공하는 데이터 스토어입니다.
https://www.oxfordsemantic.tech/rdfox
RDFox | The Knowledge Graph and Reasoning Engine
RDFox is the world's fastest knowledge graph and semantic reasoning engine. Spun out of the University of Oxford, RDFox is an enterprise-ready rules-based AI.
www.oxfordsemantic.tech
전통적으로 온톨로지 모델을 구성하기 위해서는 여러가지 방법론이 있지만 그중에서도 스탠포드 대학에서 제안한 Ontology Development 101 방법론을 주로 사용합니다. (참고 : https://joyhong.tistory.com/4)
방법론의 첫번째 단계는 온톨로지 도메인과 범위를 결정합니다.
이 글에서는 주어진 엑셀의 정보만 가지고 모델을 구성할 목적이기 때문에 간단히 온톨로지 도메인은 항공관련 논문이고, 범위와 목적은 제공하는 논문만 가지고 지식그래프를 구성하기 위함이라고 정의하고 넘어가겠습니다.
두번째 단계는 기존 온톨로지를 재사용할지를 고려합니다.
논문 데이터를 살펴보면 주로는 학술논문, 저자, 기관, 학술지, 키워드, 초록, 발행연도 에 대한 데이터가 있습니다. 따라서 별다른 어휘를 생성하거나 세분화된 온톨로지를 구축하기 보다는 기존의 잘 정의된 온톨로지를 재사용하는 것이 나은 선택으로 보입니다.
주어진 데이터셋을 잘 표현할 수 있는 기존 온톨로지는 Schema.org 에서 정의한 온톨로지가 있습니다. 그리고 용어에 대한 데이터도 다룰 것이기 때문에 SKOS 온톨로지도 재사용하면 좋은 선택이라 보여집니다. 이 외에 필요한 경우에는 별도의 어휘를 만들어 추가하도록 합니다.
세번째 단계는 중요한 항목들에 대해 분석하고 파악합니다.
이미 위에서 언급한 바와 같이 간단한 데이터셋이기 때문에 이미 중요한 항목들은 나열이 되었습니다.
그러나 이 연재의 3번째 글에서 다룰 내용이겠지만 논문의 초록으로부터 필요한 정보를 추출하여 해당 정보를 EntityNode와 EntityType으로 각각 생성하려고 합니다. 그리고 이 내용은 논문의 초록으로부터 추출한 정보이기 때문에 EntityNode와 학술논문간의 연결관계를 위한 property 1개와 EntityNode와 EntityType간의 연결관계를 위한 property 1개를 추가하도록 할 것입니다.
그래서 결과적으로 중요한 항목과 항목들간의 관계에 대한 목록은 아래와 같이 사용할 것입니다.
클래스 항목
| 주요 항목 | 클래스 어휘 |
| 학술논문 | schema:ScholarlyArticle |
| 학술지 | schema:Periodical |
| 기관 | schema:Organization |
| 저자 | schema:Person |
| 키워드 | schema:DefinedTerm |
| 주제분야 | schema:CategoryCode |
| 추출된 엔티티 | :EntityNode |
| 엔티티의 개념타입 | :EntityType |
| 개념 | skos:Concept |
| 개념집합 | skos:Collection |
관계 항목
| source 클래스 | target 클래스 | 관계 어휘 |
| schema:ScholarlyArticle | schema:Person | schema:author |
| schema:ScholarlyArticle | schema:Periodical | schema:isPartOf |
| schema:ScholarlyArticle | schema:CategoryCode | schema:about |
| schema:ScholarlyArticle | schema:DefinedTerm | schema:keywords |
| schema:Periodical | schema:Organization | schema:publisher |
| schema:Person | schema:Organization | schema:affiliaion |
| :EntityNode | schema:ScholarlyArticle | :mentionedBy |
| :EntityNode | :EntityType | :entityType |
| :EntityType | skos:Concept | dcterms:subject |
| skos:Collection | skos:Concept | skos:member |
네번째부터 여섯번째 단계는 기존의 온톨로지를 재사용하기로 결정하면서 대부분 넘어가도 되는 단계입니다.
이미 기존의 온톨로지에서 정의한 내용을 재사용하기로 한 것이기 때문에 거기서 정의한 내용을 그대로 가져와 사용할 것입니다.
여기까지의 단계를 거치게 되면 기존 온톨로지를 재사용할 경우 웹상에서 온톨로지 모델 파일을 다운받아 준비를 할 수 있게 되거나,
직접 구축을 하게 될 경우에는 다양한 도구나 프로그램을 사용하여 온톨로지 모델링을 하고 그 결과물을 파일 형태로 serialize 하게 됩니다.
이 데이터셋을 가지고 구축하려는 온톨로지 모델에 대한 간략한 도식은 아래와 같습니다.
이 글에서는 2개의 기존 온톨로지 파일(skos.ttl, schema.ttl)과 1개의 직접 생성한 온톨로지 파일(ontology.ttl)을 사용하게 됩니다.
마지막 일곱번째 단계는 인스턴스를 생성하는 단계입니다.
이 단계에서는 간단하게 파이썬 언어를 사용하여 해당 엑셀을 읽어 위에서 매핑한 어휘대로 인스턴스를 만듭니다.
# 그래프 생성
g = Graph()
# namespace 바인딩
RS = Namespace('http://joyhong.tistory.com/resource/')
ONT = Namespace('http://joyhong.tistory.com/ontology/')
SCHEMA = Namespace("http://schema.org/")
g.bind("rs", RS)
g.bind("ont", ONT)
g.bind("schema", SCHEMA)
g.bind("foaf", FOAF)
g.bind("skos", SKOS)
g.bind("dcterms", DCTERMS)
g.bind("dc", DC)
for row in df.iterrows():
article = URIRef(RS+'article_'+str(row[0]))
g.add((article, RDF.type, URIRef(SCHEMA+'ScholarlyArticle')))
g.add((article, RDFS.label, Literal(row[1]['논문명'])))
g.add((article, URIRef(SCHEMA+'datePublished'), Literal(row[1]['발행연도'])))
if row[1]['초록'] != "":
g.add((article, URIRef(SCHEMA+'abstract'), Literal(row[1]['초록'])))
if row[1]['주제분야'] != "":
about = URIRef(RS+'about_'+str(about_list.index(row[1]['주제분야'])))
g.add((article, URIRef(SCHEMA+'about'), about))
g.add((about, RDF.type, URIRef(SCHEMA+'CategoryCode')))
g.add((about, RDFS.label, Literal(row[1]['주제분야'])))
if row[1]['학술지명'] != "":
journal = URIRef(RS+'journal_'+str(journal_list.index(row[1]['학술지명'])))
g.add((article, URIRef(SCHEMA+'isPartOf'), journal))
g.add((journal, RDF.type, URIRef(SCHEMA+'Periodical')))
g.add((journal, RDFS.label, Literal(row[1]['학술지명'])))
if row[1]['발행기관명'] != "":
org = URIRef(RS+'org_'+str(org_list.index(row[1]['발행기관명'])))
g.add((journal, URIRef(SCHEMA+'publisher'), org))
g.add((org, RDF.type, URIRef(SCHEMA+'Organization')))
g.add((org, RDFS.label, Literal(row[1]['발행기관명'])))
authors = row[1]['저자명'].split(";")
authors = [x.strip() for x in authors]
for i, a in enumerate(authors):
person = URIRef(RS+'author_'+str(author_list.index(a)))
g.add((article, URIRef(SCHEMA+'author'), person))
g.add((person, RDFS.label, Literal(a)))
g.add((person, RDF.type, URIRef(SCHEMA+'Person')))
if i == 0:
org = URIRef(RS+'org_'+str(org_list.index(row[1]['주저자 소속기관'])))
g.add((person, URIRef(SCHEMA+'affiliation'), org))
g.add((org, RDF.type, URIRef(SCHEMA+'Organization')))
g.add((org, RDFS.label, Literal(row[1]['주저자 소속기관'])))
for aks in author_keyword_set[row[0]]:
g.add((article, URIRef(DC+'subject'), Literal(aks)))
g.serialize("./uam_biblio.ttl", format='turtle')
이 과정을 거치게 되면 온톨로지 모델 파일과 실제 인스턴스 파일이 준비가 됩니다.
다음으로 그래프 저장소에 해당 파일을 업로드 시키면 완성이 됩니다.
그래프 저장소는 서두에 언급한 것 처럼 RDFox를 사용할 것입니다.
RDF 그래프 저장소는 대부분 named graph 을 사용하여 별도의 공간에 데이터를 저장할 수 있도록 지원합니다.
여기서는 온톨로지 모델과 실제 인스턴스를 분리하여 각각 <http://joyhong.graph.uam/model>, <http://joyhong.graph.uam/basic> 이라는 IRI를 지정하여 저장을 하도록 할 예정입니다.
이때 named graph는 반드시 IRI 형태여야 합니다. named graph를 지정하지 않으면 default graph에 데이터가 저장됩니다.
* 이 글에서는 RDFox 사용법은 생략합니다.
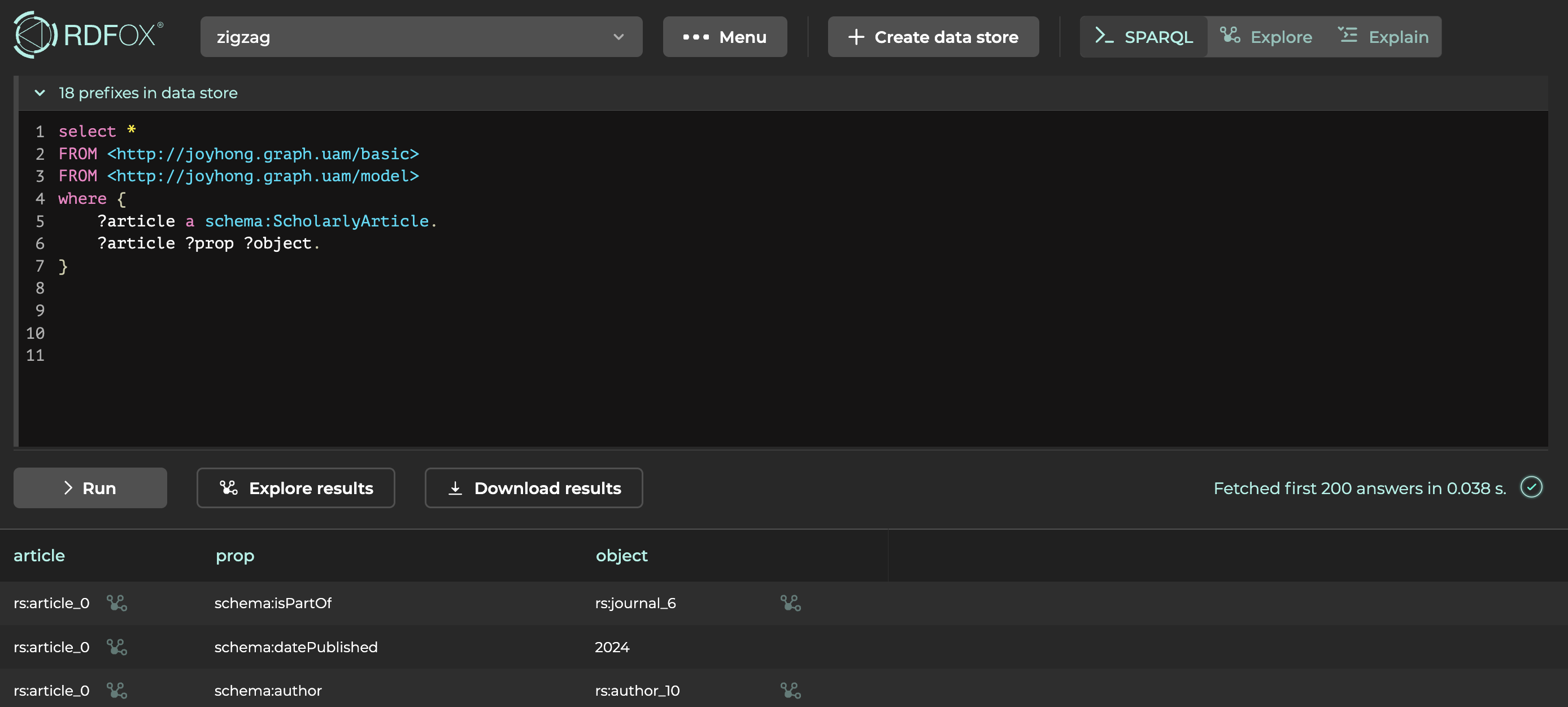
파일에 이상이 없고 업로드 과정이 성공적으로 완료되면 SPARQL을 사용하여 결과를 확인해보면 됩니다.
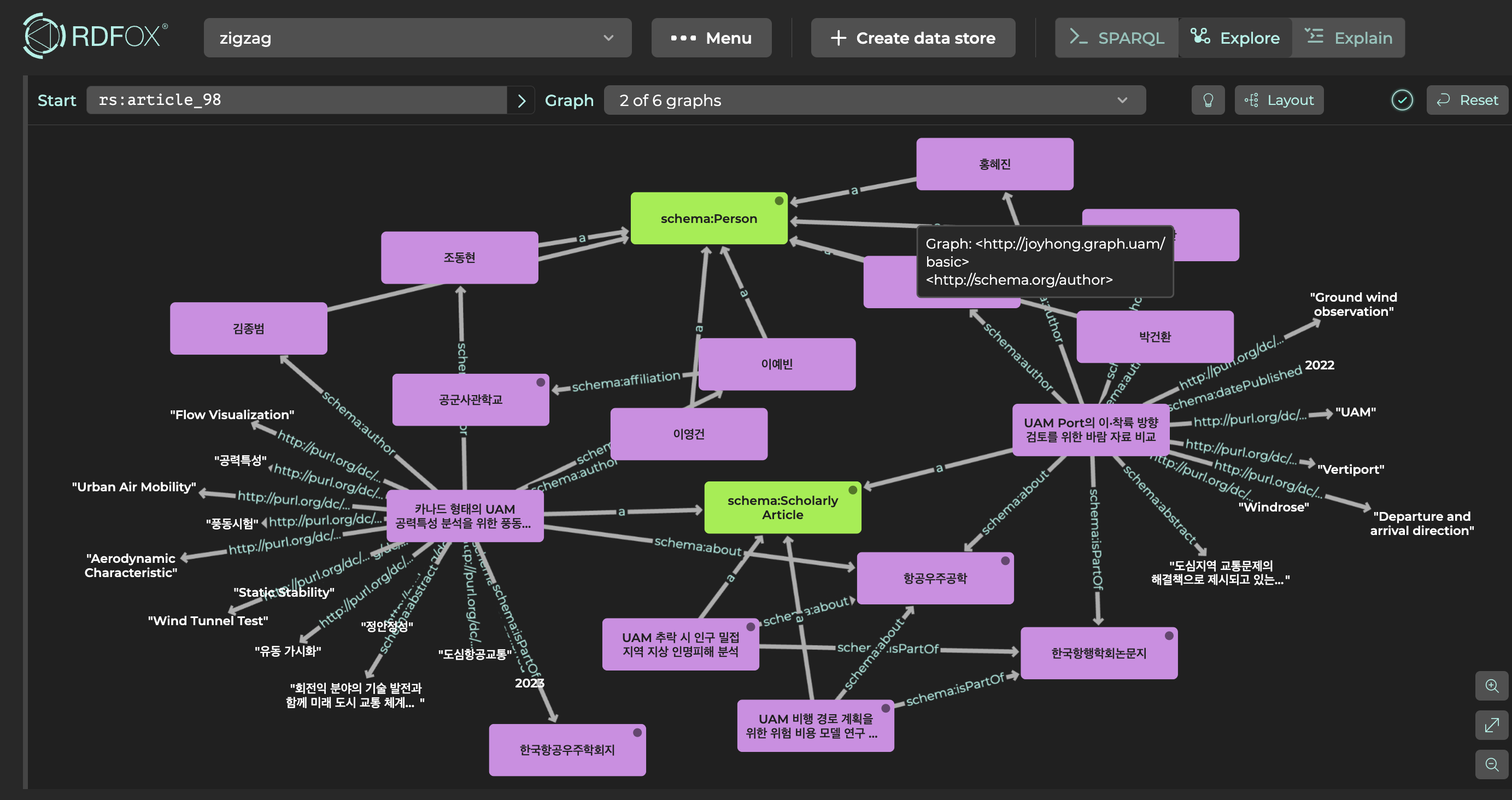
개별 논문에 대해 Explore를 활용하여 시각적으로 확인이 가능합니다.
이상으로 주어진 데이터를 통해 사람이 직접 온톨로지를 구축하고, 해당 온톨로지에 따라 실제 인스턴스를 생성하여 지식그래프를 구축하는 과정을 설명하였습니다. 그리고 그 결과물을 그래프 저장소에 업로드하여 데이터 활용에 대한 생명력을 조금 불어 넣었습니다.
다음 글에서는 데이터의 활용에 조금 더 생명력을 넣기 위해 논문의 키워드에 대한 일부 작업을 진행하는 것에 대해 작성할 예정입니다.
-끝-