
티스토리 뷰
주어진 글들에 존재하는 단어들의 동시 출현 관계를 통해 해당 글이 어떤 의미를 말하고 있는지를 파악해보면 재미있을 것 같았다. 그래서 단어, 정확히는 명사의 출현을 통해 간단히 파악할 수 있도록 구성하였다.
문장에 나타나는 명사들의 출현 거리가 가까우면 그만큼 의미있는 단어들일 것이고, 거리가 멀면 큰 관계가 없다는 전제하에 진행된다.
텍스트는 "세이노의 가르침" 이 PDF 로 무료 배포 되고 있어 이를 활용하였다.
📚세이노의 가르침 PDF/전자책 무료 배포 (2023.4.5)
종이책+전자책+PDF 📚삼총사 2탄! <세이노의 가르침>(2023.4.5) 무료 전자책과 PDF 파일을 ...
blog.naver.com
그리고 형태소 분석은 etri의 언어분석 API를 활용하였다.
AI API/DATA
인공지능 기술을 체험할 수 있는 공공 인공지능 오픈 API·DATA 서비스 포털 과기부 R&D 과제를 통해 개발된 인공지능 결과물을 체험하고 연구에 활용할 수 있도록 제공
aiopen.etri.re.kr
수행한 태스크는 아래와 같다.
1. 주어진 텍스트에서 문장 단위로 분리를 한다.
2. 문장별로 형태소 분석을 수행한다.
3. 분석된 결과에 대해 순차적으로 주변 단어 윈도우 사이즈 만큼 살피면서 명사인 경우에 한해 동시 발생을 체크한다.
4. 명사를 고유하게 식별하여 그래프의 노드로 생성한다.
5. 동시 발생한 명사들의 쌍을 그래프의 링크로 생성하고, 발생 빈도를 링크의 값으로 생성한다.
6. 발생 빈도가 일정 이하인 경우는 제거하고, isolated 된 노드도 제거한다.
7. 정제한 그래프에 대해 중심성을 계산하고, 커뮤니티 탐지를 하여 노드의 크기와 색상을 조정한다.
8. 완성된 그래프를 시각화한다.
그럼 위 내용대로 수행한 결과를 중간중간 살펴보면 아래와 같다.
예시로 사용한 텍스트의 세이노의 가르침 전체를 포함한 것이 아니라 일부 발췌하여 사용하였다.
시간이 돈이 되게 만들어라
헬라어에서 시간을 의미하는 단어는 두 개이다. 하나는 ‘크로노스’인데 흐 르는 시간을 의미한다. 이것은 우리가 어쩌지 못하는 대상으로서의 시간 이다.자동차를 타고 가다가 길이 막혀 어쩔수 없이 보내게 되는 시간 같은 것이 이 크로노스이다. 다른 하나는 ‘카이로스’인데 의미 있는 시간, 가치있는 시간, 보람있는 시간이 모두 여기에 해당된다. 이땅에서 ‘잘산다’는 것은 부자로 사는 것을 의미하는 것이 아니라 크로노스를 카이로스 로 바꾸어 살아간다는 것을 의미한다. 크로노스를 카이로스로 변화시키려는 시도가 없는 시간은 그저 세월의 주름살에 불과하다.
하지만 내가 생각하는 시간에는 크로노스와 카이로스 이외에도 하나가 더 있다. ‘돈이되는시간’이 그것이다. 흔히 시간은 금이니 돈이니 말들 하지만 크로노스로서의 시간은 전혀 돈이 안된다. 출퇴근길 복잡한 지하철 안에서 이리 볶이고 저리 볶이는 시간은 그저 지나가는 시간일 뿐이며 술에 취하여 인사불성이 되어 있는 시간도 마찬가지이다. 카이로스로서의 시간 이라고 해서 돈이 되는 것도 아니다. 예를 들어 당신이 월드컵에서 한국을 응원하느라 근 한달 동안을 축구에 모든 시간과 열정을 쏟으며 승리의 감격을 맛보고 패배의 아쉬움도 맛 보았다면 그 시간은 카이로스는 될 수 있겠지만 그 시간이 돈이 되는 것은 아니지 않는가.
부자가 되려면 ‘돈이 되는 시간’이 많아야 한다. 일을 하고 보수를 받았 다면 그 노동시간은 ‘돈이 되는 시간’에 해당된다. ‘돈이 되는 시간’은 그 시간에 임하는 사람의 태도에 따라 크로노스가 될 수도 있고 카이로스가 될수도 있다. 똑같은 일을 하여도 다람쥐 쳇바퀴 돌리듯 무심하게 무성의하게 기계적으로 한다면 그 시간은 크로노스에 지나지 않는다. 하지만 일을 개선하고자하고 자신의 힘을 모두 쏟아 부으며 최선을 다한다면 그 시간은 카이로스가 될 것이다.
‘돈이 되는 시간’은 경제적 대가가 주어지는 노동 시간만을 의미하는 것이 아니다. 지금 당장은 대가가 주어지지 않는다고 할지라도 미래에 경제적 대가가 주어지는 지식을 얻는데 사용되는 시간 역시 ‘돈이되는시간’ 에 해당된다. 예를 들어 최우수 성적으로 학교를 졸업한다면 일단은 이 사회에서 대가를 더 받게 되는데 이 경우 공부를 잘하고자 바친 시간은 ‘돈 이 되는 시간’이기도 하다.
그러나 부자가 되는 게임은 학교 성적으로만 승패가 좌우되는 것이 아니다. 부자는 세상에서 받는 대가를 크게 함으로써 될 수도 있지만 세상에 지불하여야 하는 대가를 적게함으로써 될 수도 있기 때문이다. 당신이 살아가면서 세상에 지불하는 대가는 상품이나 서비스에 대한 것이므로 ‘다른 사람들이 돈을 받고 해주는일들’에 대하여 당신이 알고 있다면 지출하는 비율이 줄어 들어 주머니에 남는 돈이 늘어나게 된다.예를 들어 웬만한 컴퓨터 고장은 직접 수리할 줄 안다면 그 수리 지식을 얻는데 사용한 시간은 ‘평생’ 컴퓨터가 고장날 때마다 돈을 절약시켜 주는 원천이 된다. ‘평생’ 말이다. 따라서 당신이 컴퓨터 하드웨어에 대하여 일단 억지로라도 배워 둔다면 그 시간은 ‘돈이 되는 시간’이 된다.
나는 이 법칙을 남들보다는 빨리 깨달았기에 시간이 날 때마다 정치나 연예인,스포츠 선수 등을 제외한 모든 것에 대하여 관심을 갖고 배우고자 하였다. 나는 길거리를 걷다가 도로공사를 하는 것을 보아도 인부들이 어떻게 하는지 세심히 바라보고 배웠다. 직접 눈으로 볼 기회가 없는 것들은 모두 책을 통해 감을 잡고 배워나갔다. 그렇게 하는 시간이 바로 ‘돈이 되는 시간’이다. 사업 초기에는 하다못해 복사기가 고장 났을 때마다 서비스 수수료 몇만원이 나가는 것이 아까워서 AS맨이 올 때마다 그가 어떻게 하는지를 옆에서 지켜보고는 나중에 수십번 이상 내가 직접 고친적도 있다. 그렇게 해서 내가 배운 분야는 하나둘이 아니다. 결혼전 내가 아내에게 보낸 첫 편지에서 겸손함없이 건방지게 하였던 말 중 하나 역시 “나는 별걸 다 아는 남자”라는 것이었다.
시간이 남는다고? 크로노스가 많다는 뜻이다. 닥치는 대로 책을 읽고 배워 나가라. 우선은 지금 하는 일과 관련된 것들부터 마스터하라. 그렇게 할때 그 시간은 ‘돈이 되는시간’이 될 수 있다. 일과 관련된 책들은 솔직히 재미는없다. 하지만 재미가 충만한 책들만을 읽는다면 그 시간은 카이로스가 될 수는 있지만 돈이 되기는 어렵다. 재미없어 보이는 지식들을 위하여 ‘돈이 되는 시간’을 먼저 투자하는 사람만이 크로노스의 굴레에서 벗어날 수 있다. 그래도 인생은 즐기며 재미있게 살아야 한다고? 장담하건대 당신이 재미있는 것만 즐기며 시간을 보내는 동안 당신의 삶 자체가 조만간 재미 없어질 것이다.
이 텍스트들을 ETRI의 API를 사용하여 분석하면 아래와 같은 결과들이 전달된다.
다른 하나는 ‘카이로스’인데 의미 있는 시간, 가치있는 시간, 보람있는 시간이 모두 여기에 해당된다
defaultdict(<class 'list'>, {0: [{'word_idx': 0, 'word': '다른', 'lemma': '다른', 'type': 'MM', 'anal_id': 0, 'label': '다른'}, {'word_idx': False, 'word': False, 'lemma': ',', 'type': 'SP', 'anal_id': 12, 'label': ','}, {'word_idx': False, 'word': False, 'lemma': ',', 'type': 'SP', 'anal_id': 17, 'label': ','}], 1: [{'word_idx': 1, 'word': '하나는', 'lemma': '하나', 'type': 'NNG', 'anal_id': 1, 'label': '하나'}, {'word_idx': 1, 'word': '하나는', 'lemma': '는', 'type': 'JX', 'anal_id': 2, 'label': '는'}], 2: [{'word_idx': 2, 'word': '‘카이로스’인데', 'lemma': '‘', 'type': 'SS', 'anal_id': 3, 'label': '‘'}, {'word_idx': 2, 'word': '‘카이로스’인데', 'lemma': '카이로스', 'type': 'NNP', 'anal_id': 4, 'label': '카이로스'}, {'word_idx': 2, 'word': '‘카이로스’인데', 'lemma': '’', 'type': 'SS', 'anal_id': 5, 'label': '’'}, {'word_idx': 2, 'word': '‘카이로스’인데', 'lemma': '이', 'type': 'VCP', 'anal_id': 6, 'label': '이'}, {'word_idx': 2, 'word': '‘카이로스’인데', 'lemma': 'ㄴ데', 'type': 'EC', 'anal_id': 7, 'label': 'ㄴ데'}], 3: [{'word_idx': 3, 'word': '의미', 'lemma': '의미', 'type': 'NNG', 'anal_id': 8, 'label': '의미'}], 4: [{'word_idx': 4, 'word': '있는', 'lemma': '있', 'type': 'VA', 'anal_id': 9, 'label': '있'}, {'word_idx': 4, 'word': '있는', 'lemma': '는', 'type': 'ETM', 'anal_id': 10, 'label': '는'}], 5: [{'word_idx': 5, 'word': '시간,', 'lemma': '시간', 'type': 'NNG', 'anal_id': 11, 'label': '시간'}], 6: [{'word_idx': 6, 'word': '가치있는', 'lemma': '가치', 'type': 'NNG', 'anal_id': 13, 'label': '가치'}, {'word_idx': 6, 'word': '가치있는', 'lemma': '있', 'type': 'VA', 'anal_id': 14, 'label': '있'}, {'word_idx': 6, 'word': '가치있는', 'lemma': '는', 'type': 'ETM', 'anal_id': 15, 'label': '는'}], 7: [{'word_idx': 7, 'word': '시간,', 'lemma': '시간', 'type': 'NNG', 'anal_id': 16, 'label': '시간'}], 8: [{'word_idx': 8, 'word': '보람있는', 'lemma': '보람', 'type': 'NNG', 'anal_id': 18, 'label': '보람'}, {'word_idx': 8, 'word': '보람있는', 'lemma': '있', 'type': 'VA', 'anal_id': 19, 'label': '있'}, {'word_idx': 8, 'word': '보람있는', 'lemma': '는', 'type': 'ETM', 'anal_id': 20, 'label': '는'}], 9: [{'word_idx': 9, 'word': '시간이', 'lemma': '시간', 'type': 'NNG', 'anal_id': 21, 'label': '시간'}, {'word_idx': 9, 'word': '시간이', 'lemma': '이', 'type': 'JKS', 'anal_id': 22, 'label': '이'}], 10: [{'word_idx': 10, 'word': '모두', 'lemma': '모두', 'type': 'MAG', 'anal_id': 23, 'label': '모두'}], 11: [{'word_idx': 11, 'word': '여기에', 'lemma': '여기', 'type': 'NP', 'anal_id': 24, 'label': '여기'}, {'word_idx': 11, 'word': '여기에', 'lemma': '에', 'type': 'JKB', 'anal_id': 25, 'label': '에'}], 12: [{'word_idx': 12, 'word': '해당된다', 'lemma': '해당', 'type': 'NNG', 'anal_id': 26, 'label': '해당'}, {'word_idx': 12, 'word': '해당된다', 'lemma': '되', 'type': 'XSV', 'anal_id': 27, 'label': '되'}, {'word_idx': 12, 'word': '해당된다', 'lemma': 'ㄴ다', 'type': 'EF', 'anal_id': 28, 'label': 'ㄴ다'}]})분석된 결과를 통해 명사 집합과 주변 단어들 중 명사가 출현하는 명사 출현 쌍을 생성한다. 이때 주변 단어를 살피는 윈도우 사이즈는 4로 설정하였다.
명사 출현 빈도가 전체 구해지면 이들 중 얼마나 많이 중복적으로 출현했는지 파악하기 위해 히스토그램을 확인하였다. 그 결과 상당히 많은 명사 동시 출현쌍이 7번 이하로 출현하였는데 여기서는 7번 이상 동시 출현이 있는 명사 쌍만 사용하기로 하여 6번 이하는 삭제하였다.
링크는 삭제하였기 때문에 노드만 남아있는 상황이 발생하기 때문에 isolated된 노드도 함께 삭제하였다.
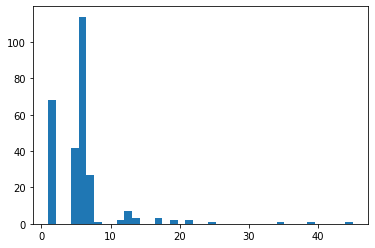
삭제하기 전의 결과를 살펴보고자 한다면 아래의 파일을 참고하세요.
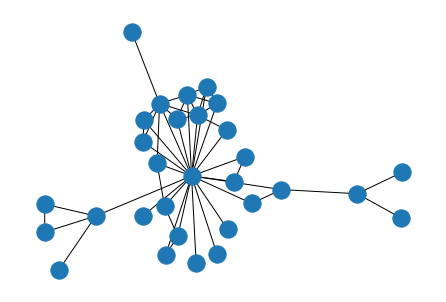
그래프는 Networkx를 사용하여 생성하였기 때문에 nx.draw() 를 통해 빠르게 살펴보면 아래와 같다.
그럼 다음으로 시각적인 효과를 주기 위해 연결중심성을 구해 노드의 크기에 포인트를 주고, 레이블 전파 알고리즘을 통해 동일한 커뮤니티에 대해 그룹핑을 하고 색상을 추가하도록 하였다. 시각화는 pyvis를 통해 구성하였다.
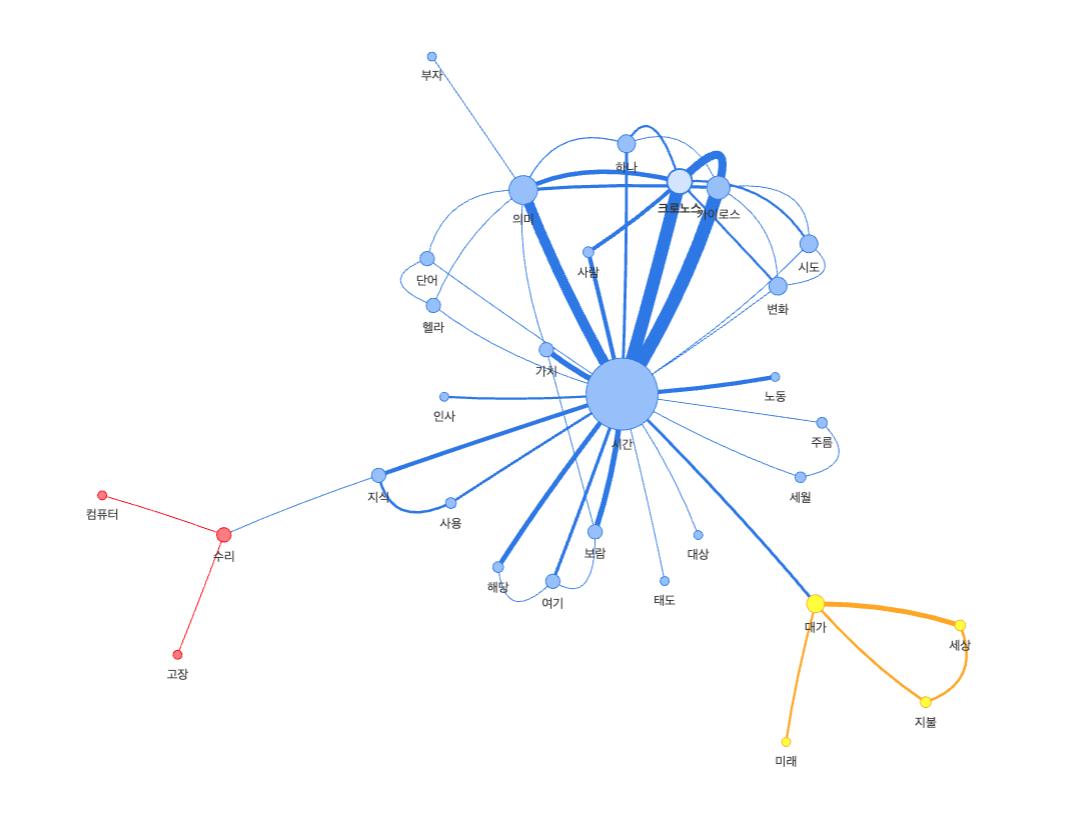
위의 내용으로 보아 서두에 사용한 텍스트들에서 "시간" 이라는 명사가 가장 많이 나왔을 것 같은 예감과, 크로노스와 카이로스가 시간이라는 단어와 함께 자주 언급되었겠다는 생각이 든다. 그리고 시간과 의미, 가치 다른 단어가 어떠한 것들을 설명하고 있을 것 같다는 생각도 든다.
이상으로 간단한 작업을 통해 주어진 특정 텍스트를 그래프로 시각화하여 살펴보기를 해보았다.
그냥 대략적인 느낌 파악을 위해서 해보는 용도로 사용하면 좋을 것 같고, 역시 글을 읽어야 제맛인것 같다.
끝.
마지막 시각화를 위해 사용한 코드는 아래와 같다.
nxg_degree_ = nx.read_gpickle("sayno_nxg_graph.gpickle")
nxg_degree_ = nxg_degree_.to_undirected()
xmin = np.min(list(degree_centrality.values()))
xmax = np.max(list(degree_centrality.values()))
degree_centrality.update((x, (((y-xmin)/(xmax - xmin))*35 +5)) for x, y in degree_centrality.items())
centrality_values = list(degree_centrality.values())
nx.set_node_attributes(nxg_degree_,degree_centrality,'size')
communities = nx_comm.label_propagation_communities(nxg_degree_)
# print(nx_comm.modularity(nxg_degree_, communities))
groups = dict()
for i, nodes in enumerate(communities):
for x in nodes:
groups[x] = i
nx.set_node_attributes(nxg_degree_, groups,'group')
nw_degree_ = Network(width='100%', height='100%', notebook=True)
nw_degree_.from_nx(nxg_degree_)
nw_degree_.show("sayno.html")'N:::만지작 거리기' 카테고리의 다른 글
| Jupyter Notebook을 통해 SPARQL 활용 (0) | 2023.08.12 |
|---|---|
| 배우들간의 공동 출연 네트워크 (0) | 2023.02.12 |
| 영화 데이터 살펴보기 with Stardog-studio (0) | 2023.02.04 |
| 10분만에 지식그래프 만들기 with Stardog (0) | 2023.01.28 |
| ontology model 생성 with Stardog Designer (0) | 2023.01.28 |
- Total
- Today
- Yesterday
- 지식그래프
- 사이퍼
- 트리플 변환
- TBC
- 스프링부트
- 온톨로지
- Knowledge Graph
- Linked Data
- RDF 변환
- cypher
- 장고
- property graph
- neosemantics
- TopBraid Composer
- sparql
- TDB
- 그래프 데이터베이스
- Neo4j
- Thymeleaf
- pyvis
- stardog
- LOD
- Ontology
- django
- RDF
- 타임리프
- MeCab
- networkx
- 지식 그래프
- 트리플
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |