[지식그래프] #3. 데이터 통합이 용이한 지식 그래프
지난 두개의 글은 arXiv의 데이터를 대상으로 용어 목록을 생성하고 개념화를 통한 지식 그래프를 구성하는 것에 대해 간략히 살펴보았습니다. 이는 의도적으로 두개를 분리를 하였습니다. 대부분이 아닐 수도 있지만 상당히 많은 곳에서 부서 혹은 조직 혹은 사용그룹마다 동일한 데이터를 중복으로 생성하고 관리를 하고 있을 것 같습니다.
여기에서는 분류체계를 예로 삼아 설명하고자 합니다. 만약 arxiv 카테고리 택소노미가 업데이트가 되었다고 하면, 우리는 (2개의 글을 각각의 서비스 혹은 시스템이라고 가정하여) 어떤 액션을 취해야 합니까? 변경된 내용을 우리의 것에 반영해야 합니다. 지금은 2개지만 서비스 혹은 시스템이 많아지면 그만큼 동일 작업을 해야 합니다.
대안은 분류체계를 관리를 누군가가 하고 이를 다른 곳에서 가져다 사용하도록 하면, 업데이트가 일어날 경우 관리를 하는 누군가만 해당 작업을 진행하면 됩니다. 나머지는 데이터를 가져다 사용하면 됩니다.
그럼 현재 2군데서 각각 생성하여 사용 중인 arxiv 분류체계를 어떻게 통합할 수 있을지 고민해볼 필요가 있습니다. 도메인이나 환경마다 각각의 상황이 있기 때문에 통합 방법에 정답은 없습니다. 이 글의 상황에서는 첫번째 글에서 생성한 용어목록 지식 그래프를 중심으로 잡고 두번째 글의 데이터를 이 용어 목록에 통합하려고 합니다. 즉 데이터를 핸들링하는 관점은 두번째 글에서 생성한 저자-논문-분류 데이터 관점이고 통합을 하려는 대상 기준은 arxiv 카테고리 택소노미입니다.
그럼 먼저 용어목록 지식 그래프에 접근을 하여 질의를 할 수 있어야 합니다. 이 예시를 위해 의도적으로 두개의 저장소에 저장을 하였습니다.(물리적으로 다른 저장소에 저장되어 있는 데이터를 재현하기 위해서..)

지식 그래프에 저장된 데이터는 웹을 통해 접근이 가능하고, SPARQL 이라는 질의 언어를 통해 질의를 할 수 있습니다. 웹상에 분산되어 존재하더라도 얼마든지 사용이 가능합니다. 우리는 저장소A에 연결된 SPARQL Endpoint에서 저장소B에 들어 있는 데이터를 조회해보도록 하겠습니다. 아래의 예시는 수학 그룹에 해당하는 skos:Concept 목록을 가져오는 질의 예시입니다.
SELECT ?c ?clabel
WHERE {
SERVICE <http://fuseki4.5:3030/arxiv/sparql> {
?c a skos:Concept .
?c skos:prefLabel ?clabel.
?c skos:broader ?brod1.
?brod1 skos:broader ?brod.
?brod skos:prefLabel "Mathematics".
}
}

이번에는 저장소A에 저장된 arxiv의 분류체계를 살펴보겠습니다. 논문이 어떤 분류에 속하는지를 나타내는 정보로 구성되어 사용하고 있습니다. 이는 Classification 이라는 개념으로 존재합니다.
SELECT *
WHERE {
?x a <http://localhost/ontology/Classification>.
?x rdfs:label ?label.
}

확실히 URI체계가 다른 것을 알 수 있습니다. 또한 클래스 유형이 다른 것도 알 수 있습니다. 데이터 통합의 경우도 정답이 따로 있는게 아니라 상황에 맞도록 통합을 진행해 나가야 합니다. 이 예시에서는 기존의 데이터를 유지하면서 저장소A의 Classification 데이터를 저장소B의 분류체계와 연결시키도록 하겠습니다.
다행스럽게 label은 같기 때문에 이를 활용하여 상호 간에 동일함을 식별하도록 하겠습니다. classification_10은 Classification 이라는 클래스의 인스턴스이고 rdfs:label로 “Number Theory”를 명시하고 있습니다. math.NT는 skos:Concept 이라는 클래스의 인스턴스이고 skos:prefLabel 로 “Number Theory”를 명시하고 있습니다. 따라서 두 저장소의 개체 중 rdfs:label과 skos:prefLabel로 명시한 레이블이 같으면, 저장소A의 논문을 저장소B의 Concept과 연결을 시킬 것입니다. 연결을 시킬 때 dcterms:subject를 통해 해당 논문의 주제는 연결이 된 Concept 이다는 의미를 부여합니다. (저장소A에서는 논문이 belongs라는 관계를 통해 Classification과 연결이 되어져 있습니다).

그럼 우선 위에서 생각한 대로 데이터가 있는지 확인해 보겠습니다.
SELECT ?c ?clabel ?x
WHERE {
{ SERVICE <http://fuseki4.5:3030/arxiv/sparql> {
?c a skos:Concept .
?c skos:prefLabel ?clabel.
?c skos:broader ?brod1.
?brod1 skos:broader ?brod.
?brod skos:prefLabel "Mathematics".
} }
{ SELECT * WHERE {
GRAPH <arxiv> {
?x rdfs:label ?clabel.
} } }
} ORDER BY ?x
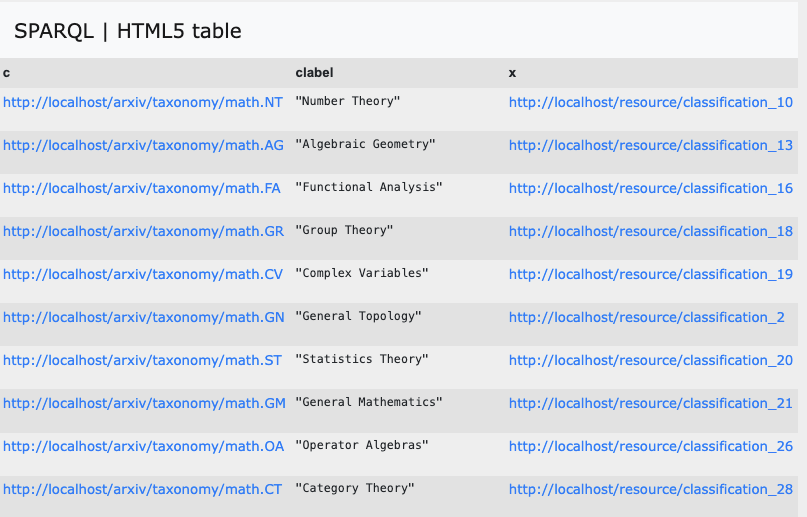
SPARQL 을 통해 질의하여 확인해보니 매칭이 되는 분류체계들이 존재합니다.
그럼 x에 해당하는 분류에 속하는 논문들도 찾아야 위에서 하고자 하는 방향대로 논문과 저장소B의 분류체계를 연결할 수 있을 것입니다.
SELECT ?c ?clabel ?x ?a
WHERE {
{ SERVICE <http://fuseki4.5:3030/arxiv/sparql> {
?c a skos:Concept .
?c skos:prefLabel ?clabel.
?c skos:broader ?brod1.
?brod1 skos:broader ?brod.
?brod skos:prefLabel "Mathematics".
} }
{ SELECT * WHERE {
GRAPH <arxiv> {
?x rdfs:label ?clabel.
?a <http://localhost/ontology/belongs> ?x.
} } }
} ORDER BY ?x
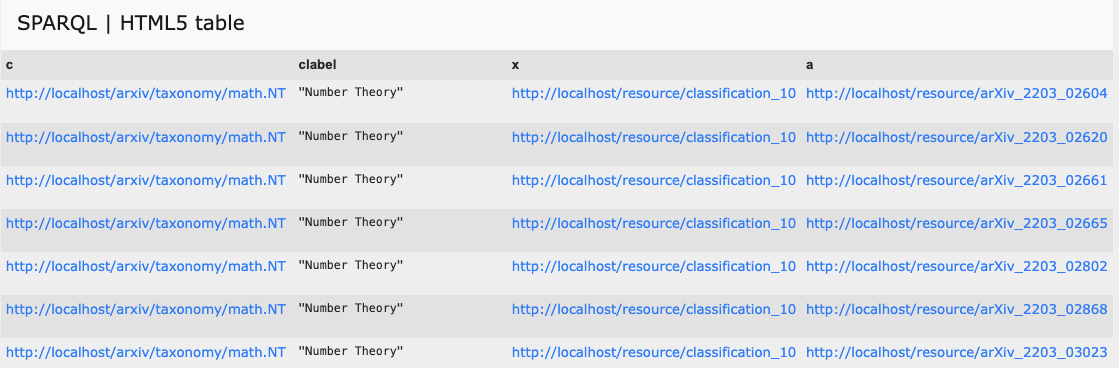
생각하고 의도한 대로 데이터들을 조회하고 찾을 수 있게 되었습니다. 그럼 이제 마지막으로 논문과 분류체계를 dcterms:subject와 연결을 시켜줘야 하는 부분만 남았습니다. 이 부분은 그래프의 유연한 구조로 인해 어렵지 않게 해결이 됩니다. 단순히 두 개체를 연결시켜주는 관계 정보만 만들어 주면 됩니다. 그럼 SPARQL 을 통해 바로 저장소에 INSERT 하겠습니다.
PREFIX dcterms: <http://purl.org/dc/terms/>
INSERT INTO GRAPH <arxiv_add> {
?a dcterms:subject ?c.
}
WHERE {
{ SERVICE <http://fuseki4.5:3030/arxiv/sparql> {
?c a skos:Concept .
?c skos:prefLabel ?clabel.
?c skos:broader ?brod1.
?brod1 skos:broader ?brod.
?brod skos:prefLabel "Mathematics".
} }
{ SELECT * WHERE {
GRAPH <arxiv> {
?x rdfs:label ?clabel.
?a <http://localhost/ontology/belongs> ?x.
} } }
}
INSERT 구문을 통해서 논문과 분류체계를 arxiv_add 그래프에 저장을 하였습니다. 저장소는 NAMED GRAPH를 지정하여 논리적으로 분리시켜 저장을 할 수 있습니다. 필요시에는 단일 GRAPH 혹은 멀티로 지정하여 활용이 가능합니다. 원래 들어있던 저장소A의 데이터는 <arxiv> 그래프에 저장되어 있었고, 조금 전 새로 생성한 데이터는 <arxiv_add> 그래프에 저장을 하였습니다. 이 두개의 그래프에 함께 질의를 하여 원데이터와 신규데이터가 잘 나오는지 확인해보겠습니다.
SELECT *
FROM <arxiv_add>
FROM <arxiv>
WHERE {
<http://localhost/resource/arXiv_2203_02315> ?p ?o.
}

데이터가 잘 만들어져서 저장되어 있고, 조회를 하는 것에도 문제가 없습니다.
이제 마지막으로 저장소B에서 가져온 택소노미 데이터를 함께 사용해 보려고 합니다. 데이터를 통합한 이유 중에 하나이기도 합니다. 저장소A에 들어 있는 데이터는 단순히 논문이 어떤 카테고리에 속하는지만 있습니다. 그러나 저장소B의 용어 목록에는 카테고리가 어떤 아카이브의 하위인지와 그 아카이브는 어떤 그룹에 속하는지 정보가 있으며, 각각의 카테고리 컨셉에는 정의가 있습니다. 이 중 컨셉의 정의와 상위 컨셉인 아카이브를 함께 조회하도록 하겠습니다.
PREFIX dcterms: <http://purl.org/dc/terms/>
SELECT *
WHERE {
{ SERVICE <http://fuseki4.5:3030/arxiv/sparql> {
?c a skos:Concept .
?c skos:prefLabel ?clabel.
?c skos:definition ?def.
?c skos:broader ?brod1.
} }
{ SELECT *
FROM <arxiv_add>
FROM <arxiv>
WHERE {
<http://localhost/resource/arXiv_2203_02315> dcterms:subject ?c.
} }
}
저장소A 만으로는 사용할 수 없는 데이터를 확장하여 사용할 수 있게 되었습니다. 뿐만 아니라 arxiv 카테고리 택소노미가 업데이트되더라도 저장소A 의 사용자는 저장소B의 관리자가 업데이트한 내용을 가져와 사용을 하면 되기 때문에 크게 관리를 할 필요가 없게 되었습니다.
비록 작은 예시이지만 위와 같은 방식으로 데이터를 관리하고 통합하여 사용하면 이점들이 많습니다. 데이터의 중복은 물론 관리의 문제도 함께 극복이 가능해 집니다. 이번 글에서는 구조화된 정보를 공유하여 사용하고자 할 때 작동할 수 있는 지식 그래프에 대해서 다루었습니다.
다음 글부터는 활용적인 관점에서 작성해보고자 합니다. 먼저는 데이터 엔지니어링 측면이 될 것입니다.
끝.